
Punctuation
Punctuation marks are marks indicating how a piece of written text should be read (silently or aloud) and, consequently, understood.[1] The oldest known examples of punctuation marks were found in the Mesha Stele from the 9th century BC, consisting of points between the words and horizontal strokes between sections.[2][further explanation needed] The alphabet-based writing began with no spaces, no capitalization, no vowels (see abjad), and with only a few punctuation marks, as it was mostly aimed at recording business transactions. Only with the Greek playwrights (such as Euripides and Aristophanes) did the ends of sentences begin to be marked to help actors know when to make a pause during performances. Punctuation includes space between words and both obsolete and modern signs.
By the 19th century, the punctuation marks were used hierarchically, according to their weight.[3] Six marks, proposed in 1966 by the French author Hervé Bazin, could be seen as predecessors of emoticons and emojis.[4]
In rare cases, the meaning of a text can be changed substantially by using different punctuation, such as in "woman, without her man, is nothing" (emphasizing the importance of men to women), contrasted with "woman: without her, man is nothing" (emphasizing the importance of women to men).[5] Similar changes in meaning can be achieved in spoken forms of most languages by using elements of speech such as suprasegmentals. The rules of punctuation vary with the language, location, register, and time. In online chat and text messages punctuation is used tachygraphically, especially among younger users.
History
Punctuation marks, especially spacing, were not needed in logographic or syllabic (such as Chinese and Mayan script) texts because disambiguation and emphasis could be communicated by employing a separate written form distinct from the spoken form of the language. Ancient Chinese classical texts were transmitted without punctuation. However, many Warring States period bamboo texts contain the symbols ⟨└⟩ and ⟨▄⟩ indicating the end of a chapter and full stop, respectively.[6] By the Song dynasty, the addition of punctuation to texts by scholars to aid comprehension became common.[7]
Western antiquity
During antiquity, most scribes in the West wrote in scriptio continua, i.e. without punctuation delimiting word boundaries. Around the 5th century BC, the Greeks began using punctuation consisting of vertically arranged dots—usually a dicolon or tricolon—as an aid in the oral delivery of texts. After 200 BC, Greek scribes adopted the théseis system invented by Aristophanes of Byzantium, where a single dot called a punctus was placed at one of several heights to denote rhetorical divisions in speech:
- hypostigmḗ – a low punctus on the baseline to mark off a komma (a unit smaller than a clause)
- stigmḕ mésē – a punctus at midheight to mark off a clause (kōlon)
- stigmḕ teleía – a high punctus to mark off a sentence (periodos)[8]
In addition, the Greeks used the paragraphos (or gamma) to mark the beginning of sentences, marginal diples to mark quotations, and a koronis to indicate the end of major sections.
During the 1st century BC, Romans also made occasional use of symbols to indicate pauses, but by the 4th century AD the Greek théseis—called distinctiones in Latin[a]—prevailed, as reported by Aelius Donatus and Isidore of Seville (7th century). Latin texts were sometimes laid out per capitula, where each sentence was placed on its own line. Diples were used, but by the late period these often degenerated into comma-shaped marks.
Medieval
Punctuation developed dramatically when large numbers of copies of the Bible started to be produced. These were designed to be read aloud, so the copyists began to introduce a range of marks to aid the reader, including indentation, various punctuation marks (diple, paragraphos, simplex ductus), and an early version of initial capitals (litterae notabiliores). Jerome and his colleagues, who made a translation of the Bible into Latin, the Vulgate (c. AD 400), employed a layout system based on established practices for teaching the speeches of Demosthenes and Cicero. Under his layout per cola et commata every sense-unit was indented and given its own line. This layout was solely used for biblical manuscripts during the 5th–9th centuries but was abandoned in favor of punctuation.
In the 7th–8th centuries Irish and Anglo-Saxon scribes, whose native languages were not derived from Latin, added more visual cues to render texts more intelligible. Irish scribes introduced the practice of word separation.[9] Likewise, insular scribes adopted the distinctiones system while adapting it for minuscule script (so as to be more prominent) by using not differing height but rather a differing number of marks—aligned horizontally (or sometimes triangularly)—to signify a pause's duration: one mark for a minor pause, two for a medium one, and three for a major one. Most common were the punctus, a comma-shaped mark, and a 7-shaped mark (comma positura), often used in combination. The same marks could be used in the margin to mark off quotations.
In the late 8th century a different system emerged in France under the Carolingian dynasty. Originally indicating how the voice should be modulated when chanting the liturgy, the positurae migrated into any text meant to be read aloud, and then to all manuscripts. Positurae first reached England in the late 10th century, probably during the Benedictine reform movement, but was not adopted until after the Norman conquest. The original positurae were the punctus, punctus elevatus,[10] punctus versus, and punctus interrogativus, but a fifth symbol, the punctus flexus, was added in the 10th century to indicate a pause of a value between the punctus and punctus elevatus. In the late 11th/early 12th century the punctus versus disappeared and was taken over by the simple punctus (now with two distinct values).[11]
The late Middle Ages saw the addition of the virgula suspensiva (slash or slash with a midpoint dot) which was often used in conjunction with the punctus for different types of pauses. Direct quotations were marked with marginal diples, as in Antiquity, but from at least the 12th century scribes also began entering diples (sometimes double) within the column of text.
Printing-press era
The amount of printed material and its readership began to increase after the invention of moveable type in Europe in the 1450s. Martin Luther's German Bible translation was one of the first mass printed works, he used only virgule, full stop and less than one percent question marks as punctuation. The focus of punctuation still was rhetorical, to aid reading aloud.[12] As explained by writer and editor Lynne Truss, "The rise of printing in the 14th and 15th centuries meant that a standard system of punctuation was urgently required."[13] Printed books, whose letters were uniform, could be read much more rapidly than manuscripts. Rapid reading, or reading aloud, did not allow time to analyze sentence structures. This increased speed led to the greater use and finally standardization of punctuation, which showed the relationships of words with each other: where one sentence ends and another begins, for example.
The introduction of a standard system of punctuation has also been attributed to the Venetian printers Aldus Manutius and his grandson. They have been credited with popularizing the practice of ending sentences with the colon or full stop (period), inventing the semicolon, making occasional use of parentheses, and creating the modern comma by lowering the virgule. By 1566, Aldus Manutius the Younger was able to state that the main object of punctuation was the clarification of syntax.[14]
By the 19th century, punctuation in the Western world had evolved "to classify the marks hierarchically, in terms of weight".[15] Cecil Hartley's poem identifies their relative values:
The stop point out, with truth, the time of pause
A sentence doth require at ev'ry clause.
At ev'ry comma, stop while one you count;
At semicolon, two is the amount;
A colon doth require the time of three;
The period four, as learned men agree.[16]
The use of punctuation was not standardised until after the invention of printing. According to the 1885 edition of The American Printer, the importance of punctuation was noted in various sayings by children, such as:
Charles the First walked and talked
Half an hour after his head was cut off.
With a semicolon and a comma added, it reads as follows:
Charles the First walked and talked;
Half an hour after, his head was cut off.[17]
In a 19th-century manual of typography, Thomas MacKellar writes:
Shortly after the invention of printing, the necessity of stops or pauses in sentences for the guidance of the reader produced the colon and full point. In process of time, the comma was added, which was then merely a perpendicular line, proportioned to the body of the letter. These three points were the only ones used until the close of the fifteenth century, when Aldo Manuccio gave a better shape to the comma, and added the semicolon; the comma denoting the shortest pause, the semicolon next, then the colon, and the full point terminating the sentence. The marks of interrogation and admiration were introduced many years after.[18]
Typewriters and electronic communication
The introduction of electrical telegraphy with a limited set of transmission codes[19] and typewriters with a limited set of keys influenced punctuation subtly. For example, curved quotes and apostrophes were all collapsed into two characters (' and "). The hyphen, minus sign, and dashes of various widths have been collapsed into a single character (-), sometimes repeated to represent a long dash. The spaces of different widths available to professional typesetters were generally replaced by a single full-character width space, with typefaces monospaced. In some cases a typewriter keyboard did not include an exclamation point (!), which could otherwise be constructed by the overstrike of an apostrophe and a period; the original Morse code did not have an exclamation point.
These simplifications have been carried forward into digital writing, with teleprinters and the ASCII character set essentially supporting the same characters as typewriters. Treatment of whitespace in HTML discouraged the practice (in English prose) of putting two full spaces after a full stop, since a single or double space would appear the same on the screen. (Most style guides now discourage double spaces, and some electronic writing tools, including Wikipedia's software, automatically collapse double spaces to single.) The full traditional set of typesetting tools became available with the advent of desktop publishing and more sophisticated word processors. Despite the widespread adoption of character sets like Unicode that support the punctuation of traditional typesetting, writing forms like text messages tend to use the simplified ASCII style of punctuation, with the addition of new non-text characters like emoji. Informal text speak tends to drop punctuation when not needed, including some ways that would be considered errors in more formal writing.
In the computer era, punctuation characters were recycled for use in programming languages and URLs. Due to its use in email and Twitter handles, the at sign (@) has gone from an obscure character mostly used by sellers of bulk commodities (10 pounds @$2.00 per pound), to a very common character in common use for both technical routing and an abbreviation for "at". The tilde (~), in moveable type only used in combination with vowels, for mechanical reasons ended up as a separate key on mechanical typewriters, and like @ it has been put to completely new uses.
In English
There are two major styles of punctuation in English: British or American. These two styles differ mainly in the way in which they handle quotation marks, particularly in conjunction with other punctuation marks. In British English, punctuation marks such as full stops and commas are placed inside the quotation mark only if they are part of what is being quoted, and placed outside the closing quotation mark if part of the containing sentence. In American English, however, such punctuation is generally placed inside the closing quotation mark regardless. This rule varies for other punctuation marks; for example, American English follows the British English rule when it comes to semicolons, colons, question marks, and exclamation points.[20][further explanation needed] The serial comma is used much more often in the United States than in the UK.
Other languages
This section needs additional citations for verification. (November 2020) |
Other languages of Europe use much the same punctuation as English. The similarity is so strong that the few variations may confuse a native English reader. Quotation marks are particularly variable across European languages. For example, in French and Russian, quotes would appear as: « Je suis fatigué. » (In French, the quotation marks are spaced from the enclosed material; in Russian they are not.)
In the French of France and Belgium, the marks ⟨:⟩, ⟨;⟩, ⟨?⟩ and ⟨!⟩ are preceded by a thin space. In Canadian French, this is only the case for ⟨:⟩.[21][22]
In Greek, the question mark is written as the English semicolon, while the functions of the colon and semicolon are performed by a raised point ⟨·⟩, known as the ano teleia (άνω τελεία).
In Georgian, three dots ⟨჻⟩ were formerly used as a sentence or paragraph divider. It is still sometimes used in calligraphy.
Spanish and Asturian (both of them Romance languages used in Spain) use an inverted question mark ⟨¿⟩ at the beginning of a question and the normal question mark at the end, as well as an inverted exclamation mark ⟨¡⟩ at the beginning of an exclamation and the normal exclamation mark at the end.[23]
Armenian uses several punctuation marks of its own. The full stop is represented by a colon, and vice versa; the exclamation mark is represented by a diagonal similar to a tilde ⟨~⟩, while the question mark ⟨՞⟩ resembles an unclosed circle placed after the last vowel of the word.
Arabic, Urdu, and Persian—written from right to left—use a reversed question mark: ⟨؟⟩, and a reversed comma: ⟨،⟩. This is a modern innovation; pre-modern Arabic did not use punctuation. Hebrew, which is also written from right to left, uses the same characters as in English, ⟨,⟩ and ⟨?⟩.[24]
Originally, Sanskrit had no punctuation. In the 17th century, Sanskrit and Marathi, both written using Devanagari, started using the vertical bar ⟨।⟩ to end a line of prose and double vertical bars ⟨॥⟩ in verse.
Punctuation was not used in Chinese, Japanese, Korean and Vietnamese Chu Nom writing until the adoption of punctuation from the West in the late 19th and early 20th century. In unpunctuated texts, the grammatical structure of sentences in classical writing is inferred from context.[25] Most punctuation marks in modern Chinese, Japanese, and Korean have similar functions to their English counterparts; however, they often look different and have different customary rules.
In the Indian subcontinent, ⟨:-⟩ is sometimes used in place of colon or after a subheading. Its origin is unclear, but could be a remnant of the British Raj. Another punctuation common in the Indian Subcontinent for writing monetary amounts is the use of ⟨/-⟩ or ⟨/=⟩ after the number. For example, Rs. 20/- or Rs. 20/= implies 20 whole rupees.
Thai, Khmer, Lao and Burmese did not use punctuation until the adoption of punctuation from the West in the 20th century. Blank spaces are more frequent than full stops or commas.
Novel punctuation marks
Interrobang
In 1962, American advertising executive Martin K. Speckter proposed the interrobang (‽), a combination of the question mark and exclamation point, to mark rhetorical questions or questions stated in a tone of disbelief. Although the new punctuation mark was widely discussed in the 1960s, it failed to achieve widespread use.[26] Nevertheless, it and its inverted form were given code points in Unicode: U+203D ‽ INTERROBANG, U+2E18 ⸘ INVERTED INTERROBANG.
Predecessors of emoticons and emojis
The six additional punctuation marks proposed in 1966 by the French author Hervé Bazin in his book Plumons l'Oiseau ("Let's pluck the bird", 1966)[27] could be seen as predecessors of emoticons and emojis.
These were:[28]
- the "irony point" or "irony mark" (point d'ironie:
 )
) - the "love point" (point d'amour:
 )
) 
A point d'amour mark, or "love point" - the "conviction point" (point de conviction:
 )
) - the "authority point" (point d'autorité:
 )
) - the "acclamation point" (point d'acclamation:
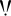 )
) - the "doubt point" (point de doute:
 )
)
_%E2%80%93_variant.svg?lang=en)
"Question comma", "exclamation comma"

An international patent application was filed, and published in 1992 under World Intellectual Property Organization (WIPO) number WO9219458,[29] for two new punctuation marks: the "question comma" and the "exclamation comma". The question comma has a comma instead of the dot at the bottom of a question mark, while the exclamation comma has a comma in place of the point at the bottom of an exclamation mark. These were intended for use as question and exclamation marks within a sentence, a function for which normal question and exclamation marks can also be used, but which may be considered obsolescent. The patent application entered into the national phase only in Canada. It was advertised as lapsing in Australia on 27 January 1994[30] and in Canada on 6 November 1995.[31]
Others
Other proposed punctuation marks include:[32]
- Snark mark, indicating an ironic statement by putting a tilde next to terminal punctuation: .~ for dry sarcasm, !~ for enthusiastic sarcasm, and ?~ for sarcastic questions
- Rhetorical question mark:

- SarcMark for sarcasm
Punctuation marks in Unicode
| By Unicode General Category 'P' |
| § Pd, dash |
| § Ps-Pe, start–end (open–close brackets) |
| § Pi-Pf, initial–final quote |
| § Pc, connector |
| § Po, other |
| Mark | Name | Code point | General Category | Script | |
|---|---|---|---|---|---|
| Pd, dash | |||||
| - | HYPHEN-MINUS | U+002D | Pd, dash | Common | |
| ‐ | HYPHEN | U+2010 | Pd, dash | Common | |
| ‑ | NON-BREAKING HYPHEN | U+2011 | Pd, dash | Common | |
| ‒ | FIGURE DASH | U+2012 | Pd, dash | Common | |
| – | EN DASH | U+2013 | Pd, dash | Common | |
| — | EM DASH | U+2014 | Pd, dash | Common | |
| ― | HORIZONTAL BAR | U+2015 | Pd, dash | Common | |
| ⸗ | DOUBLE OBLIQUE HYPHEN | U+2E17 | Pd, dash | Common | |
| ⸚ | HYPHEN WITH DIAERESIS | U+2E1A | Pd, dash | Common | |
| ⸺ | TWO-EM DASH | U+2E3A | Pd, dash | Common | |
| ⸻ | THREE-EM DASH | U+2E3B | Pd, dash | Common | |
| ⹀ | DOUBLE HYPHEN | U+2E40 | Pd, dash | Common | |
| 〜 | WAVE DASH | U+301C | Pd, dash | Common | |
| 〰 | WAVY DASH | U+3030 | Pd, dash | Common | |
| ゠ | KATAKANA-HIRAGANA DOUBLE HYPHEN | U+30A0 | Pd, dash | Common | |
| ︱ | PRESENTATION FORM FOR VERTICAL EM DASH | U+FE31 | Pd, dash | Common | |
| ︲ | PRESENTATION FORM FOR VERTICAL EN DASH | U+FE32 | Pd, dash | Common | |
| ﹘ | SMALL EM DASH | U+FE58 | Pd, dash | Common | |
| ﹣ | SMALL HYPHEN-MINUS | U+FE63 | Pd, dash | Common | |
| - | FULLWIDTH HYPHEN-MINUS | U+FF0D | Pd, dash | Common | |
| ֊ | ARMENIAN HYPHEN | U+058A | Pd, dash | Armenian | |
| ᐀ | CANADIAN SYLLABICS HYPHEN | U+1400 | Pd, dash | Canadian Aboriginal | |
| ־ | HEBREW PUNCTUATION MAQAF | U+05BE | Pd, dash | Hebrew | |
| ᠆ | MONGOLIAN TODO SOFT HYPHEN | U+1806 | Pd, dash | Mongolian | |
| 𐺭 | YEZIDI HYPHENATION MARK | U+10EAD | Pd, dash | Yezidi | |
| Pi-Pf, initial–final quote | |||||
| « » |
|
|
|
Common | |
| ‘ ’ |
|
|
|
Common | |
| ‛ | SINGLE HIGH-REVERSED-9 QUOTATION MARK | U+201B | Pi, initial quote | Common | |
| “ ” |
|
|
|
Common | |
| ‟ | DOUBLE HIGH-REVERSED-9 QUOTATION MARK | U+201F | Pi, initial quote | Common | |
| ‹ › |
|
|
|
Common | |
| ⸂ ⸃ |
|
|
|
Common | |
| ⸄ ⸅ |
|
|
|
Common | |
| ⸉ ⸊ |
|
|
|
Common | |
| ⸌ ⸍ |
|
|
|
Common | |
| ⸜ ⸝ |
|
|
|
Common | |
| ⸠ ⸡ |
|
|
|
Common | |
| Ps-Pe, open–close (brackets) | |||||
| ( ) |
|
|
|
Common | |
| [ ] |
|
|
|
Common | |
| { } |
|
|
|
Common | |
| ‚ | SINGLE LOW-9 QUOTATION MARK | U+201A | Ps, open | Common | |
| „ | DOUBLE LOW-9 QUOTATION MARK | U+201E | Ps, open | Common | |
| ⁅ ⁆ |
|
|
|
Common | |
| ⁽ ⁾ |
|
|
|
Common | |
| ₍ ₎ |
|
|
|
Common | |
| ⌈ ⌉ |
|
|
|
Common | |
| ⌊ ⌋ |
|
|
|
Common | |
| 〈 〉 |
|
|
|
Common | |
| ❨ ❩ |
|
|
|
Common | |
| ❪ ❫ |
|
|
|
Common | |
| ❬ ❭ |
|
|
|
Common | |
| ❮ ❯ |
|
|
|
Common | |
| ❰ ❱ |
|
|
|
Common | |
| ❲ ❳ |
|
|
|
Common | |
| ❴ ❵ |
|
|
|
Common | |
| ⟅ ⟆ |
|
|
|
Common | |
| ⟦ ⟧ |
|
|
|
Common | |
| ⟨ ⟩ |
|
|
|
Common | |
| ⟪ ⟫ |
|
|
|
Common | |
| ⟬ ⟭ |
|
|
|
Common | |
| ⟮ ⟯ |
|
|
|
Common | |
| ⦃ ⦄ |
|
|
|
Common | |
| ⦅ ⦆ |
|
|
|
Common | |
| ⦇ ⦈ |
|
|
|
Common | |
| ⦉ ⦊ |
|
|
|
Common | |
| ⦋ ⦌ |
|
|
|
Common | |
| ⦍ ⦎ |
|
|
|
Common | |
| ⦏ ⦐ |
|
|
|
Common | |
| ⦑ ⦒ |
|
|
|
Common | |
| ⦓ ⦔ |
|
|
|
Common | |
| ⦕ ⦖ |
|
|
|
Common | |
| ⦗ ⦘ |
|
|
|
Common | |
| ⧘ ⧙ |
|
|
|
Common | |
| ⧚ ⧛ |
|
|
|
Common | |
| ⧼ ⧽ |
|
|
|
Common | |
| ⸢ ⸣ |
|
|
|
Common | |
| ⸤ ⸥ |
|
|
|
Common | |
| ⸦ ⸧ |
|
|
|
Common | |
| ⸨ ⸩ |
|
|
|
Common | |
| ⹂ | DOUBLE LOW-REVERSED-9 QUOTATION MARK | U+2E42 | Ps, open | Common | |
| 〈 〉 |
|
|
|
Common | |
| 《 》 |
|
|
|
Common | |
| 「 」 |
|
|
|
Common | |
| 『 』 |
|
|
|
Common | |
| 【 】 |
|
|
|
Common | |
| 〔 〕 |
|
|
|
Common | |
| 〖 〗 |
|
|
|
Common | |
| 〘 〙 |
|
|
|
Common | |
| 〚 〛 |
|
|
|
Common | |
| 〝 〞 |
|
|
|
Common | |
| 〟 | LOW DOUBLE PRIME QUOTATION MARK | U+301F | Pe, close | Common | |
| ﴿ | ORNATE RIGHT PARENTHESIS | U+FD3F | Ps, open | Common | |
| ︗ ︘ |
|
|
|
Common | |
| ︵ ︶ |
|
|
|
Common | |
| ︷ ︸ |
|
|
|
Common | |
| ︹ ︺ |
|
|
|
Common | |
| ︻ ︼ |
|
|
|
Common | |
| ︽ ︾ |
|
|
|
Common | |
| ︿ ﹀ |
|
|
|
Common | |
| ﹁ ﹂ |
|
|
|
Common | |
| ﹃ ﹄ |
|
|
|
Common | |
| ﹇ ﹈ |
|
|
|
Common | |
| ﹙ ﹚ |
|
|
|
Common | |
| ﹛ ﹜ |
|
|
|
Common | |
| ﹝ ﹞ |
|
|
|
Common | |
| ( ) |
|
|
|
Common | |
| [ ] |
|
|
|
Common | |
| { } |
|
|
|
Common | |
| ⦅ ⦆ |
|
|
|
Common | |
| 「 」 |
|
|
|
Common | |
| ᚛ ᚜ |
|
|
|
Ogham | |
| ༺ ༻ |
|
|
|
Tibetan | |
| ༼ ༽ |
|
|
|
Tibetan | |
| Pc, connector | |||||
| _ | LOW LINE | U+005F | Pc, connector | Common | |
| ‿ | UNDERTIE | U+203F | Pc, connector | Common | |
| ⁀ | CHARACTER TIE | U+2040 | Pc, connector | Common | |
| ⁔ | INVERTED UNDERTIE | U+2054 | Pc, connector | Common | |
| ︳ | PRESENTATION FORM FOR VERTICAL LOW LINE | U+FE33 | Pc, connector | Common | |
| ︴ | PRESENTATION FORM FOR VERTICAL WAVY LOW LINE | U+FE34 | Pc, connector | Common | |
| ﹍ | DASHED LOW LINE | U+FE4D | Pc, connector | Common | |
| ﹎ | CENTRELINE LOW LINE | U+FE4E | Pc, connector | Common | |
| ﹏ | WAVY LOW LINE | U+FE4F | Pc, connector | Common | |
| _ | FULLWIDTH LOW LINE | U+FF3F | Pc, connector | Common | |
| Po, other | |||||
| ! | EXCLAMATION MARK | U+0021 | Po, other | Common | |
| " | QUOTATION MARK | U+0022 | Po, other | Common | |
| # | NUMBER SIGN | U+0023 | Po, other | Common | |
| % | PERCENT SIGN | U+0025 | Po, other | Common | |
| & | AMPERSAND | U+0026 | Po, other | Common | |
| ' | APOSTROPHE | U+0027 | Po, other | Common | |
| * | ASTERISK | U+002A | Po, other | Common | |
| , | COMMA | U+002C | Po, other | Common | |
| . | FULL STOP | U+002E | Po, other | Common | |
| / | SOLIDUS | U+002F | Po, other | Common | |
| : | COLON | U+003A | Po, other | Common | |
| ; | SEMICOLON | U+003B | Po, other | Common | |
| ? | QUESTION MARK | U+003F | Po, other | Common | |
| @ | COMMERCIAL AT | U+0040 | Po, other | Common | |
| \ | REVERSE SOLIDUS | U+005C | Po, other | Common | |
| ¡ | INVERTED EXCLAMATION MARK | U+00A1 | Po, other | Common | |
| § | SECTION SIGN | U+00A7 | Po, other | Common | |
| ¶ | PILCROW SIGN | U+00B6 | Po, other | Common | |
| · | MIDDLE DOT | U+00B7 | Po, other | Common | |
| ¿ | INVERTED QUESTION MARK | U+00BF | Po, other | Common | |
| ; | GREEK QUESTION MARK | U+037E | Po, other | Common | |
| · | GREEK ANO TELEIA | U+0387 | Po, other | Common | |
| ، | ARABIC COMMA | U+060C | Po, other | Common | |
| ؛ | ARABIC SEMICOLON | U+061B | Po, other | Common | |
| ؟ | ARABIC QUESTION MARK | U+061F | Po, other | Common | |
| । | DEVANAGARI DANDA | U+0964 | Po, other | Common | |
| ॥ | DEVANAGARI DOUBLE DANDA | U+0965 | Po, other | Common | |
| ჻ | GEORGIAN PARAGRAPH SEPARATOR | U+10FB | Po, other | Common | |
| ᛫ | RUNIC SINGLE PUNCTUATION | U+16EB | Po, other | Common | |
| ᛬ | RUNIC MULTIPLE PUNCTUATION | U+16EC | Po, other | Common | |
| ᛭ | RUNIC CROSS PUNCTUATION | U+16ED | Po, other | Common | |
| ᜵ | PHILIPPINE SINGLE PUNCTUATION | U+1735 | Po, other | Common | |
| ᜶ | PHILIPPINE DOUBLE PUNCTUATION | U+1736 | Po, other | Common | |
| ᠂ | MONGOLIAN COMMA | U+1802 | Po, other | Common | |
| ᠃ | MONGOLIAN FULL STOP | U+1803 | Po, other | Common | |
| ᠅ | MONGOLIAN FOUR DOTS | U+1805 | Po, other | Common | |
| ᳓ | VEDIC SIGN NIHSHVASA | U+1CD3 | Po, other | Common | |
| ‖ | DOUBLE VERTICAL LINE | U+2016 | Po, other | Common | |
| ‗ | DOUBLE LOW LINE | U+2017 | Po, other | Common | |
| † | DAGGER | U+2020 | Po, other | Common | |
| ‡ | DOUBLE DAGGER | U+2021 | Po, other | Common | |
| • | BULLET | U+2022 | Po, other | Common | |
| ‣ | TRIANGULAR BULLET | U+2023 | Po, other | Common | |
| ․ | ONE DOT LEADER | U+2024 | Po, other | Common | |
| ‥ | TWO DOT LEADER | U+2025 | Po, other | Common | |
| … | HORIZONTAL ELLIPSIS | U+2026 | Po, other | Common | |
| ‧ | HYPHENATION POINT | U+2027 | Po, other | Common | |
| ‰ | PER MILLE SIGN | U+2030 | Po, other | Common | |
| ‱ | PER TEN THOUSAND SIGN | U+2031 | Po, other | Common | |
| ′ | PRIME | U+2032 | Po, other | Common | |
| ″ | DOUBLE PRIME | U+2033 | Po, other | Common | |
| ‴ | TRIPLE PRIME | U+2034 | Po, other | Common | |
| ‵ | REVERSED PRIME | U+2035 | Po, other | Common | |
| ‶ | REVERSED DOUBLE PRIME | U+2036 | Po, other | Common | |
| ‷ | REVERSED TRIPLE PRIME | U+2037 | Po, other | Common | |
| ‸ | CARET | U+2038 | Po, other | Common | |
| ※ | REFERENCE MARK | U+203B | Po, other | Common | |
| ‼ | DOUBLE EXCLAMATION MARK | U+203C | Po, other | Common | |
| ‽ | INTERROBANG | U+203D | Po, other | Common | |
| ‾ | OVERLINE | U+203E | Po, other | Common | |
| ⁁ | CARET INSERTION POINT | U+2041 | Po, other | Common | |
| ⁂ | ASTERISM | U+2042 | Po, other | Common | |
| ⁃ | HYPHEN BULLET | U+2043 | Po, other | Common | |
| ⁇ | DOUBLE QUESTION MARK | U+2047 | Po, other | Common | |
| ⁈ | QUESTION EXCLAMATION MARK | U+2048 | Po, other | Common | |
| ⁉ | EXCLAMATION QUESTION MARK | U+2049 | Po, other | Common | |
| ⁊ | TIRONIAN SIGN ET | U+204A | Po, other | Common | |
| ⁋ | REVERSED PILCROW SIGN | U+204B | Po, other | Common | |
| ⁌ | BLACK LEFTWARDS BULLET | U+204C | Po, other | Common | |
| ⁍ | BLACK RIGHTWARDS BULLET | U+204D | Po, other | Common | |
| ⁎ | LOW ASTERISK | U+204E | Po, other | Common | |
| ⁏ | REVERSED SEMICOLON | U+204F | Po, other | Common | |
| ⁐ | CLOSE UP | U+2050 | Po, other | Common | |
| ⁑ | TWO ASTERISKS ALIGNED VERTICALLY | U+2051 | Po, other | Common | |
| ⁓ | SWUNG DASH | U+2053 | Po, other | Common | |
| ⁕ | FLOWER PUNCTUATION MARK | U+2055 | Po, other | Common | |
| ⁖ | THREE DOT PUNCTUATION | U+2056 | Po, other | Common | |
| ⁗ | QUADRUPLE PRIME | U+2057 | Po, other | Common | |
| ⁘ | FOUR DOT PUNCTUATION | U+2058 | Po, other | Common | |
| ⁙ | FIVE DOT PUNCTUATION | U+2059 | Po, other | Common | |
| ⁚ | TWO DOT PUNCTUATION | U+205A | Po, other | Common | |
| ⁛ | FOUR DOT MARK | U+205B | Po, other | Common | |
| ⁜ | DOTTED CROSS | U+205C | Po, other | Common | |
| ⁝ | TRICOLON | U+205D | Po, other | Common | |
| ⁞ | VERTICAL FOUR DOTS | U+205E | Po, other | Common | |
| ⸀ | RIGHT ANGLE SUBSTITUTION MARKER | U+2E00 | Po, other | Common | |
| ⸁ | RIGHT ANGLE DOTTED SUBSTITUTION MARKER | U+2E01 | Po, other | Common | |
| ⸆ | RAISED INTERPOLATION MARKER | U+2E06 | Po, other | Common | |
| ⸇ | RAISED DOTTED INTERPOLATION MARKER | U+2E07 | Po, other | Common | |
| ⸈ | DOTTED TRANSPOSITION MARKER | U+2E08 | Po, other | Common | |
| ⸋ | RAISED SQUARE | U+2E0B | Po, other | Common | |
| ⸎ | EDITORIAL CORONIS | U+2E0E | Po, other | Common | |
| ⸏ | PARAGRAPHOS | U+2E0F | Po, other | Common | |
| ⸐ | FORKED PARAGRAPHOS | U+2E10 | Po, other | Common | |
| ⸑ | REVERSED FORKED PARAGRAPHOS | U+2E11 | Po, other | Common | |
| ⸒ | HYPODIASTOLE | U+2E12 | Po, other | Common | |
| ⸓ | DOTTED OBELOS | U+2E13 | Po, other | Common | |
| ⸔ | DOWNWARDS ANCORA | U+2E14 | Po, other | Common | |
| ⸕ | UPWARDS ANCORA | U+2E15 | Po, other | Common | |
| ⸖ | DOTTED RIGHT-POINTING ANGLE | U+2E16 | Po, other | Common | |
| ⸘ | INVERTED INTERROBANG | U+2E18 | Po, other | Common | |
| ⸙ | PALM BRANCH | U+2E19 | Po, other | Common | |
| ⸛ | TILDE WITH RING ABOVE | U+2E1B | Po, other | Common | |
| ⸞ | TILDE WITH DOT ABOVE | U+2E1E | Po, other | Common | |
| ⸟ | TILDE WITH DOT BELOW | U+2E1F | Po, other | Common | |
| ⸪ | TWO DOTS OVER ONE DOT PUNCTUATION | U+2E2A | Po, other | Common | |
| ⸫ | ONE DOT OVER TWO DOTS PUNCTUATION | U+2E2B | Po, other | Common | |
| ⸬ | SQUARED FOUR DOT PUNCTUATION | U+2E2C | Po, other | Common | |
| ⸭ | FIVE DOT MARK | U+2E2D | Po, other | Common | |
| ⸮ | REVERSED QUESTION MARK | U+2E2E | Po, other | Common | |
| ⸰ | RING POINT | U+2E30 | Po, other | Common | |
| ⸱ | WORD SEPARATOR MIDDLE DOT | U+2E31 | Po, other | Common | |
| ⸲ | TURNED COMMA | U+2E32 | Po, other | Common | |
| ⸳ | RAISED DOT | U+2E33 | Po, other | Common | |
| ⸴ | RAISED COMMA | U+2E34 | Po, other | Common | |
| ⸵ | TURNED SEMICOLON | U+2E35 | Po, other | Common | |
| ⸶ | DAGGER WITH LEFT GUARD | U+2E36 | Po, other | Common | |
| ⸷ | DAGGER WITH RIGHT GUARD | U+2E37 | Po, other | Common | |
| ⸸ | TURNED DAGGER | U+2E38 | Po, other | Common | |
| ⸹ | TOP HALF SECTION SIGN | U+2E39 | Po, other | Common | |
| ⸼ | STENOGRAPHIC FULL STOP | U+2E3C | Po, other | Common | |
| ⸽ | VERTICAL SIX DOTS | U+2E3D | Po, other | Common | |
| ⸾ | WIGGLY VERTICAL LINE | U+2E3E | Po, other | Common | |
| ⸿ | CAPITULUM | U+2E3F | Po, other | Common | |
| ⹁ | REVERSED COMMA | U+2E41 | Po, other | Common | |
| ⹃ | DASH WITH LEFT UPTURN | U+2E43 | Po, other | Common | |
| ⹄ | DOUBLE SUSPENSION MARK | U+2E44 | Po, other | Common | |
| ⹅ | INVERTED LOW KAVYKA | U+2E45 | Po, other | Common | |
| ⹆ | INVERTED LOW KAVYKA WITH KAVYKA ABOVE | U+2E46 | Po, other | Common | |
| ⹇ | LOW KAVYKA | U+2E47 | Po, other | Common | |
| ⹈ | LOW KAVYKA WITH DOT | U+2E48 | Po, other | Common | |
| ⹉ | DOUBLE STACKED COMMA | U+2E49 | Po, other | Common | |
| ⹊ | DOTTED SOLIDUS | U+2E4A | Po, other | Common | |
| ⹋ | TRIPLE DAGGER | U+2E4B | Po, other | Common | |
| ⹌ | MEDIEVAL COMMA | U+2E4C | Po, other | Common | |
| ⹍ | PARAGRAPHUS MARK | U+2E4D | Po, other | Common | |
| ⹎ | PUNCTUS ELEVATUS MARK | U+2E4E | Po, other | Common | |
| ⹏ | CORNISH VERSE DIVIDER | U+2E4F | Po, other | Common | |
| ⹒ | TIRONIAN SIGN CAPITAL ET | U+2E52 | Po, other | Common | |
| 、 | IDEOGRAPHIC COMMA | U+3001 | Po, other | Common | |
| 。 | IDEOGRAPHIC FULL STOP | U+3002 | Po, other | Common | |
| 〃 | DITTO MARK | U+3003 | Po, other | Common | |
| 〽 | PART ALTERNATION MARK | U+303D | Po, other | Common | |
| ・ | KATAKANA MIDDLE DOT | U+30FB | Po, other | Common | |
| ꤮ | KAYAH LI SIGN CWI | U+A92E | Po, other | Common | |
| ︐ | PRESENTATION FORM FOR VERTICAL COMMA | U+FE10 | Po, other | Common | |
| ︑ | PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC COMMA | U+FE11 | Po, other | Common | |
| ︒ | PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC FULL STOP | U+FE12 | Po, other | Common | |
| ︓ | PRESENTATION FORM FOR VERTICAL COLON | U+FE13 | Po, other | Common | |
| ︔ | PRESENTATION FORM FOR VERTICAL SEMICOLON | U+FE14 | Po, other | Common | |
| ︕ | PRESENTATION FORM FOR VERTICAL EXCLAMATION MARK | U+FE15 | Po, other | Common | |
| ︖ | PRESENTATION FORM FOR VERTICAL QUESTION MARK | U+FE16 | Po, other | Common | |
| ︙ | PRESENTATION FORM FOR VERTICAL HORIZONTAL ELLIPSIS | U+FE19 | Po, other | Common | |
| ︰ | PRESENTATION FORM FOR VERTICAL TWO DOT LEADER | U+FE30 | Po, other | Common | |
| ﹅ | SESAME DOT | U+FE45 | Po, other | Common | |
| ﹆ | WHITE SESAME DOT | U+FE46 | Po, other | Common | |
| ﹉ | DASHED OVERLINE | U+FE49 | Po, other | Common | |
| ﹊ | CENTRELINE OVERLINE | U+FE4A | Po, other | Common | |
| ﹋ | WAVY OVERLINE | U+FE4B | Po, other | Common | |
| ﹌ | DOUBLE WAVY OVERLINE | U+FE4C | Po, other | Common | |
| ﹐ | SMALL COMMA | U+FE50 | Po, other | Common | |
| ﹑ | SMALL IDEOGRAPHIC COMMA | U+FE51 | Po, other | Common | |
| ﹒ | SMALL FULL STOP | U+FE52 | Po, other | Common | |
| ﹔ | SMALL SEMICOLON | U+FE54 | Po, other | Common | |
| ﹕ | SMALL COLON | U+FE55 | Po, other | Common | |
| ﹖ | SMALL QUESTION MARK | U+FE56 | Po, other | Common | |
| ﹗ | SMALL EXCLAMATION MARK | U+FE57 | Po, other | Common | |
| ﹟ | SMALL NUMBER SIGN | U+FE5F | Po, other | Common | |
| ﹠ | SMALL AMPERSAND | U+FE60 | Po, other | Common | |
| ﹡ | SMALL ASTERISK | U+FE61 | Po, other | Common | |
| ﹨ | SMALL REVERSE SOLIDUS | U+FE68 | Po, other | Common | |
| ﹪ | SMALL PERCENT SIGN | U+FE6A | Po, other | Common | |
| ﹫ | SMALL COMMERCIAL AT | U+FE6B | Po, other | Common | |
| ! | FULLWIDTH EXCLAMATION MARK | U+FF01 | Po, other | Common | |
| " | FULLWIDTH QUOTATION MARK | U+FF02 | Po, other | Common | |
| # | FULLWIDTH NUMBER SIGN | U+FF03 | Po, other | Common | |
| % | FULLWIDTH PERCENT SIGN | U+FF05 | Po, other | Common | |
| & | FULLWIDTH AMPERSAND | U+FF06 | Po, other | Common | |
| ' | FULLWIDTH APOSTROPHE | U+FF07 | Po, other | Common | |
| * | FULLWIDTH ASTERISK | U+FF0A | Po, other | Common | |
| , | FULLWIDTH COMMA | U+FF0C | Po, other | Common | |
| . | FULLWIDTH FULL STOP | U+FF0E | Po, other | Common | |
| / | FULLWIDTH SOLIDUS | U+FF0F | Po, other | Common | |
| : | FULLWIDTH COLON | U+FF1A | Po, other | Common | |
| ; | FULLWIDTH SEMICOLON | U+FF1B | Po, other | Common | |
| ? | FULLWIDTH QUESTION MARK | U+FF1F | Po, other | Common | |
| @ | FULLWIDTH COMMERCIAL AT | U+FF20 | Po, other | Common | |
| \ | FULLWIDTH REVERSE SOLIDUS | U+FF3C | Po, other | Common | |
| 。 | HALFWIDTH IDEOGRAPHIC FULL STOP | U+FF61 | Po, other | Common | |
| 、 | HALFWIDTH IDEOGRAPHIC COMMA | U+FF64 | Po, other | Common | |
| ・ | HALFWIDTH KATAKANA MIDDLE DOT | U+FF65 | Po, other | Common | |
| 𐄀 | AEGEAN WORD SEPARATOR LINE | U+10100 | Po, other | Common | |
| 𐄁 | AEGEAN WORD SEPARATOR DOT | U+10101 | Po, other | Common | |
| 𐄂 | AEGEAN CHECK MARK | U+10102 | Po, other | Common | |
| 𖿢 | OLD CHINESE HOOK MARK | U+16FE2 | Po, other | Common | |
| 𞥞 | ADLAM INITIAL EXCLAMATION MARK | U+1E95E | Po, other | Adlam | |
| 𞥟 | ADLAM INITIAL QUESTION MARK | U+1E95F | Po, other | Adlam | |
| ՚ | ARMENIAN APOSTROPHE | U+055A | Po, other | Armenian | |
| ՛ | ARMENIAN EMPHASIS MARK | U+055B | Po, other | Armenian | |
| ՜ | ARMENIAN EXCLAMATION MARK | U+055C | Po, other | Armenian | |
| ՝ | ARMENIAN COMMA | U+055D | Po, other | Armenian | |
| ՞ | ARMENIAN QUESTION MARK | U+055E | Po, other | Armenian | |
| ՟ | ARMENIAN ABBREVIATION MARK | U+055F | Po, other | Armenian | |
| ։ | ARMENIAN FULL STOP | U+0589 | Po, other | Armenian | |
| ؉ | ARABIC-INDIC PER MILLE SIGN | U+0609 | Po, other | Arabic | |
| ؊ | ARABIC-INDIC PER TEN THOUSAND SIGN | U+060A | Po, other | Arabic | |
| ؍ | ARABIC DATE SEPARATOR | U+060D | Po, other | Arabic | |
| ؞ | ARABIC TRIPLE DOT PUNCTUATION MARK | U+061E | Po, other | Arabic | |
| ٪ | ARABIC PERCENT SIGN | U+066A | Po, other | Arabic | |
| ٫ | ARABIC DECIMAL SEPARATOR | U+066B | Po, other | Arabic | |
| ٬ | ARABIC THOUSANDS SEPARATOR | U+066C | Po, other | Arabic | |
| ٭ | ARABIC FIVE POINTED STAR | U+066D | Po, other | Arabic | |
| ۔ | ARABIC FULL STOP | U+06D4 | Po, other | Arabic | |
| 𑜼 | AHOM SIGN SMALL SECTION | U+1173C | Po, other | Ahom | |
| 𑜽 | AHOM SIGN SECTION | U+1173D | Po, other | Ahom | |
| 𑜾 | AHOM SIGN RULAI | U+1173E | Po, other | Ahom | |
| 𐬹 | AVESTAN ABBREVIATION MARK | U+10B39 | Po, other | Avestan | |
| 𐬺 | TINY TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3A | Po, other | Avestan | |
| 𐬻 | SMALL TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3B | Po, other | Avestan | |
| 𐬼 | LARGE TWO DOTS OVER ONE DOT PUNCTUATION | U+10B3C | Po, other | Avestan | |
| 𐬽 | LARGE ONE DOT OVER TWO DOTS PUNCTUATION | U+10B3D | Po, other | Avestan | |
| 𐬾 | LARGE TWO RINGS OVER ONE RING PUNCTUATION | U+10B3E | Po, other | Avestan | |
| 𐬿 | LARGE ONE RING OVER TWO RINGS PUNCTUATION | U+10B3F | Po, other | Avestan | |
| ᭚ | BALINESE PANTI | U+1B5A | Po, other | Balinese | |
| ᭛ | BALINESE PAMADA | U+1B5B | Po, other | Balinese | |
| ᭜ | BALINESE WINDU | U+1B5C | Po, other | Balinese | |
| ᭝ | BALINESE CARIK PAMUNGKAH | U+1B5D | Po, other | Balinese | |
| ᭞ | BALINESE CARIK SIKI | U+1B5E | Po, other | Balinese | |
| ᭟ | BALINESE CARIK PAREREN | U+1B5F | Po, other | Balinese | |
| ᭠ | BALINESE PAMENENG | U+1B60 | Po, other | Balinese | |
| ꛲ | BAMUM NJAEMLI | U+A6F2 | Po, other | Bamum | |
| ꛳ | BAMUM FULL STOP | U+A6F3 | Po, other | Bamum | |
| ꛴ | BAMUM COLON | U+A6F4 | Po, other | Bamum | |
| ꛵ | BAMUM COMMA | U+A6F5 | Po, other | Bamum | |
| ꛶ | BAMUM SEMICOLON | U+A6F6 | Po, other | Bamum | |
| ꛷ | BAMUM QUESTION MARK | U+A6F7 | Po, other | Bamum | |
| 𖫵 | BASSA VAH FULL STOP | U+16AF5 | Po, other | Bassa Vah | |
| ᯼ | BATAK SYMBOL BINDU NA METEK | U+1BFC | Po, other | Batak | |
| ᯽ | BATAK SYMBOL BINDU PINARBORAS | U+1BFD | Po, other | Batak | |
| ᯾ | BATAK SYMBOL BINDU JUDUL | U+1BFE | Po, other | Batak | |
| ᯿ | BATAK SYMBOL BINDU PANGOLAT | U+1BFF | Po, other | Batak | |
| ৽ | BENGALI ABBREVIATION SIGN | U+09FD | Po, other | Bengali | |
| 𑱁 | BHAIKSUKI DANDA | U+11C41 | Po, other | Bhaiksuki | |
| 𑱂 | BHAIKSUKI DOUBLE DANDA | U+11C42 | Po, other | Bhaiksuki | |
| 𑱃 | BHAIKSUKI WORD SEPARATOR | U+11C43 | Po, other | Bhaiksuki | |
| 𑱄 | BHAIKSUKI GAP FILLER-1 | U+11C44 | Po, other | Bhaiksuki | |
| 𑱅 | BHAIKSUKI GAP FILLER-2 | U+11C45 | Po, other | Bhaiksuki | |
| 𑁇 | BRAHMI DANDA | U+11047 | Po, other | Brahmi | |
| 𑁈 | BRAHMI DOUBLE DANDA | U+11048 | Po, other | Brahmi | |
| 𑁉 | BRAHMI PUNCTUATION DOT | U+11049 | Po, other | Brahmi | |
| 𑁊 | BRAHMI PUNCTUATION DOUBLE DOT | U+1104A | Po, other | Brahmi | |
| 𑁋 | BRAHMI PUNCTUATION LINE | U+1104B | Po, other | Brahmi | |
| 𑁌 | BRAHMI PUNCTUATION CRESCENT BAR | U+1104C | Po, other | Brahmi | |
| 𑁍 | BRAHMI PUNCTUATION LOTUS | U+1104D | Po, other | Brahmi | |
| ᨞ | BUGINESE PALLAWA | U+1A1E | Po, other | Buginese | |
| ᨟ | BUGINESE END OF SECTION | U+1A1F | Po, other | Buginese | |
| ᙮ | CANADIAN SYLLABICS FULL STOP | U+166E | Po, other | Canadian Aboriginal | |
| 𑅀 | CHAKMA SECTION MARK | U+11140 | Po, other | Chakma | |
| 𑅁 | CHAKMA DANDA | U+11141 | Po, other | Chakma | |
| 𑅂 | CHAKMA DOUBLE DANDA | U+11142 | Po, other | Chakma | |
| 𑅃 | CHAKMA QUESTION MARK | U+11143 | Po, other | Chakma | |
| ꩜ | CHAM PUNCTUATION SPIRAL | U+AA5C | Po, other | Cham | |
| ꩝ | CHAM PUNCTUATION DANDA | U+AA5D | Po, other | Cham | |
| ꩞ | CHAM PUNCTUATION DOUBLE DANDA | U+AA5E | Po, other | Cham | |
| ꩟ | CHAM PUNCTUATION TRIPLE DANDA | U+AA5F | Po, other | Cham | |
| ⳹ | COPTIC OLD NUBIAN FULL STOP | U+2CF9 | Po, other | Coptic | |
| ⳺ | COPTIC OLD NUBIAN DIRECT QUESTION MARK | U+2CFA | Po, other | Coptic | |
| ⳻ | COPTIC OLD NUBIAN INDIRECT QUESTION MARK | U+2CFB | Po, other | Coptic | |
| ⳼ | COPTIC OLD NUBIAN VERSE DIVIDER | U+2CFC | Po, other | Coptic | |
| ⳾ | COPTIC FULL STOP | U+2CFE | Po, other | Coptic | |
| ⳿ | COPTIC MORPHOLOGICAL DIVIDER | U+2CFF | Po, other | Coptic | |
| 𒑰 | CUNEIFORM PUNCTUATION SIGN OLD ASSYRIAN WORD DIVIDER | U+12470 | Po, other | Cuneiform | |
| 𒑱 | CUNEIFORM PUNCTUATION SIGN VERTICAL COLON | U+12471 | Po, other | Cuneiform | |
| 𒑲 | CUNEIFORM PUNCTUATION SIGN DIAGONAL COLON | U+12472 | Po, other | Cuneiform | |
| 𒑳 | CUNEIFORM PUNCTUATION SIGN DIAGONAL TRICOLON | U+12473 | Po, other | Cuneiform | |
| 𒑴 | CUNEIFORM PUNCTUATION SIGN DIAGONAL QUADCOLON | U+12474 | Po, other | Cuneiform | |
| ꙳ | SLAVONIC ASTERISK | U+A673 | Po, other | Cyrillic | |
| ꙾ | CYRILLIC KAVYKA | U+A67E | Po, other | Cyrillic | |
| 𐕯 | CAUCASIAN ALBANIAN CITATION MARK | U+1056F | Po, other | Caucasian Albanian | |
| ॰ | DEVANAGARI ABBREVIATION SIGN | U+0970 | Po, other | Devanagari | |
| ꣸ | DEVANAGARI SIGN PUSHPIKA | U+A8F8 | Po, other | Devanagari | |
| ꣹ | DEVANAGARI GAP FILLER | U+A8F9 | Po, other | Devanagari | |
| ꣺ | DEVANAGARI CARET | U+A8FA | Po, other | Devanagari | |
| ꣼ | DEVANAGARI SIGN SIDDHAM | U+A8FC | Po, other | Devanagari | |
| 𑥄 | DIVES AKURU DOUBLE DANDA | U+11944 | Po, other | Dives Akuru | |
| 𑥅 | DIVES AKURU GAP FILLER | U+11945 | Po, other | Dives Akuru | |
| 𑥆 | DIVES AKURU END OF TEXT MARK | U+11946 | Po, other | Dives Akuru | |
| 𑠻 | DOGRA ABBREVIATION SIGN | U+1183B | Po, other | Dogra | |
| 𛲟 | DUPLOYAN PUNCTUATION CHINOOK FULL STOP | U+1BC9F | Po, other | Duployan | |
| ፠ | ETHIOPIC SECTION MARK | U+1360 | Po, other | Ethiopic | |
| ፡ | ETHIOPIC WORDSPACE | U+1361 | Po, other | Ethiopic | |
| ። | ETHIOPIC FULL STOP | U+1362 | Po, other | Ethiopic | |
| ፣ | ETHIOPIC COMMA | U+1363 | Po, other | Ethiopic | |
| ፤ | ETHIOPIC SEMICOLON | U+1364 | Po, other | Ethiopic | |
| ፥ | ETHIOPIC COLON | U+1365 | Po, other | Ethiopic | |
| ፦ | ETHIOPIC PREFACE COLON | U+1366 | Po, other | Ethiopic | |
| ፧ | ETHIOPIC QUESTION MARK | U+1367 | Po, other | Ethiopic | |
| ፨ | ETHIOPIC PARAGRAPH SEPARATOR | U+1368 | Po, other | Ethiopic | |
| ੶ | GURMUKHI ABBREVIATION SIGN | U+0A76 | Po, other | Gurmukhi | |
| ૰ | GUJARATI ABBREVIATION SIGN | U+0AF0 | Po, other | Gujarati | |
| ׀ | HEBREW PUNCTUATION PASEQ | U+05C0 | Po, other | Hebrew | |
| ׃ | HEBREW PUNCTUATION SOF PASUQ | U+05C3 | Po, other | Hebrew | |
| ׆ | HEBREW PUNCTUATION NUN HAFUKHA | U+05C6 | Po, other | Hebrew | |
| ׳ | HEBREW PUNCTUATION GERESH | U+05F3 | Po, other | Hebrew | |
| ״ | HEBREW PUNCTUATION GERSHAYIM | U+05F4 | Po, other | Hebrew | |
| 𐡗 | IMPERIAL ARAMAIC SECTION SIGN | U+10857 | Po, other | Imperial Aramaic | |
| ꧁ | JAVANESE LEFT RERENGGAN | U+A9C1 | Po, other | Javanese | |
| ꧂ | JAVANESE RIGHT RERENGGAN | U+A9C2 | Po, other | Javanese | |
| ꧃ | JAVANESE PADA ANDAP | U+A9C3 | Po, other | Javanese | |
| ꧄ | JAVANESE PADA MADYA | U+A9C4 | Po, other | Javanese | |
| ꧅ | JAVANESE PADA LUHUR | U+A9C5 | Po, other | Javanese | |
| ꧆ | JAVANESE PADA WINDU | U+A9C6 | Po, other | Javanese | |
| ꧇ | JAVANESE PADA PANGKAT | U+A9C7 | Po, other | Javanese | |
| ꧈ | JAVANESE PADA LINGSA | U+A9C8 | Po, other | Javanese | |
| ꧉ | JAVANESE PADA LUNGSI | U+A9C9 | Po, other | Javanese | |
| ꧊ | JAVANESE PADA ADEG | U+A9CA | Po, other | Javanese | |
| ꧋ | JAVANESE PADA ADEG ADEG | U+A9CB | Po, other | Javanese | |
| ꧌ | JAVANESE PADA PISELEH | U+A9CC | Po, other | Javanese | |
| ꧍ | JAVANESE TURNED PADA PISELEH | U+A9CD | Po, other | Javanese | |
| ꧞ | JAVANESE PADA TIRTA TUMETES | U+A9DE | Po, other | Javanese | |
| ꧟ | JAVANESE PADA ISEN-ISEN | U+A9DF | Po, other | Javanese | |
| 𑂻 | KAITHI ABBREVIATION SIGN | U+110BB | Po, other | Kaithi | |
| 𑂼 | KAITHI ENUMERATION SIGN | U+110BC | Po, other | Kaithi | |
| 𑂾 | KAITHI SECTION MARK | U+110BE | Po, other | Kaithi | |
| 𑂿 | KAITHI DOUBLE SECTION MARK | U+110BF | Po, other | Kaithi | |
| 𑃀 | KAITHI DANDA | U+110C0 | Po, other | Kaithi | |
| 𑃁 | KAITHI DOUBLE DANDA | U+110C1 | Po, other | Kaithi | |
| ಄ | KANNADA SIGN SIDDHAM | U+0C84 | Po, other | Kannada | |
| ꤯ | KAYAH LI SIGN SHYA | U+A92F | Po, other | Kayah Li | |
| 𐩐 | KHAROSHTHI PUNCTUATION DOT | U+10A50 | Po, other | Kharoshthi | |
| 𐩑 | KHAROSHTHI PUNCTUATION SMALL CIRCLE | U+10A51 | Po, other | Kharoshthi | |
| 𐩒 | KHAROSHTHI PUNCTUATION CIRCLE | U+10A52 | Po, other | Kharoshthi | |
| 𐩓 | KHAROSHTHI PUNCTUATION CRESCENT BAR | U+10A53 | Po, other | Kharoshthi | |
| 𐩔 | KHAROSHTHI PUNCTUATION MANGALAM | U+10A54 | Po, other | Kharoshthi | |
| 𐩕 | KHAROSHTHI PUNCTUATION LOTUS | U+10A55 | Po, other | Kharoshthi | |
| 𐩖 | KHAROSHTHI PUNCTUATION DANDA | U+10A56 | Po, other | Kharoshthi | |
| 𐩗 | KHAROSHTHI PUNCTUATION DOUBLE DANDA | U+10A57 | Po, other | Kharoshthi | |
| 𐩘 | KHAROSHTHI PUNCTUATION LINES | U+10A58 | Po, other | Kharoshthi | |
| ។ | KHMER SIGN KHAN | U+17D4 | Po, other | Khmer | |
| ៕ | KHMER SIGN BARIYOOSAN | U+17D5 | Po, other | Khmer | |
| ៖ | KHMER SIGN CAMNUC PII KUUH | U+17D6 | Po, other | Khmer | |
| ៘ | KHMER SIGN BEYYAL | U+17D8 | Po, other | Khmer | |
| ៙ | KHMER SIGN PHNAEK MUAN | U+17D9 | Po, other | Khmer | |
| ៚ | KHMER SIGN KOOMUUT | U+17DA | Po, other | Khmer | |
| 𑈸 | KHOJKI DANDA | U+11238 | Po, other | Khojki | |
| 𑈹 | KHOJKI DOUBLE DANDA | U+11239 | Po, other | Khojki | |
| 𑈺 | KHOJKI WORD SEPARATOR | U+1123A | Po, other | Khojki | |
| 𑈻 | KHOJKI SECTION MARK | U+1123B | Po, other | Khojki | |
| 𑈼 | KHOJKI DOUBLE SECTION MARK | U+1123C | Po, other | Khojki | |
| 𑈽 | KHOJKI ABBREVIATION SIGN | U+1123D | Po, other | Khojki | |
| ᰻ | LEPCHA PUNCTUATION TA-ROL | U+1C3B | Po, other | Lepcha | |
| ᰼ | LEPCHA PUNCTUATION NYET THYOOM TA-ROL | U+1C3C | Po, other | Lepcha | |
| ᰽ | LEPCHA PUNCTUATION CER-WA | U+1C3D | Po, other | Lepcha | |
| ᰾ | LEPCHA PUNCTUATION TSHOOK CER-WA | U+1C3E | Po, other | Lepcha | |
| ᰿ | LEPCHA PUNCTUATION TSHOOK | U+1C3F | Po, other | Lepcha | |
| ᥄ | LIMBU EXCLAMATION MARK | U+1944 | Po, other | Limbu | |
| ᥅ | LIMBU QUESTION MARK | U+1945 | Po, other | Limbu | |
| ꓾ | LISU PUNCTUATION COMMA | U+A4FE | Po, other | Lisu | |
| ꓿ | LISU PUNCTUATION FULL STOP | U+A4FF | Po, other | Lisu | |
| 𐤿 | LYDIAN TRIANGULAR MARK | U+1093F | Po, other | Lydian | |
| 𑅴 | MAHAJANI ABBREVIATION SIGN | U+11174 | Po, other | Mahajani | |
| 𑅵 | MAHAJANI SECTION MARK | U+11175 | Po, other | Mahajani | |
| 𑻷 | MAKASAR PASSIMBANG | U+11EF7 | Po, other | Makasar | |
| 𑻸 | MAKASAR END OF SECTION | U+11EF8 | Po, other | Makasar | |
| 𐫰 | MANICHAEAN PUNCTUATION STAR | U+10AF0 | Po, other | Manichaean | |
| 𐫱 | MANICHAEAN PUNCTUATION FLEURON | U+10AF1 | Po, other | Manichaean | |
| 𐫲 | MANICHAEAN PUNCTUATION DOUBLE DOT WITHIN DOT | U+10AF2 | Po, other | Manichaean | |
| 𐫳 | MANICHAEAN PUNCTUATION DOT WITHIN DOT | U+10AF3 | Po, other | Manichaean | |
| 𐫴 | MANICHAEAN PUNCTUATION DOT | U+10AF4 | Po, other | Manichaean | |
| 𐫵 | MANICHAEAN PUNCTUATION TWO DOTS | U+10AF5 | Po, other | Manichaean | |
| 𐫶 | MANICHAEAN PUNCTUATION LINE FILLER | U+10AF6 | Po, other | Manichaean | |
| 𑱰 | MARCHEN HEAD MARK | U+11C70 | Po, other | Marchen | |
| 𑱱 | MARCHEN MARK SHAD | U+11C71 | Po, other | Marchen | |
| 𖺗 | MEDEFAIDRIN COMMA | U+16E97 | Po, other | Medefaidrin | |
| 𖺘 | MEDEFAIDRIN FULL STOP | U+16E98 | Po, other | Medefaidrin | |
| 𖺙 | MEDEFAIDRIN SYMBOL AIVA | U+16E99 | Po, other | Medefaidrin | |
| 𖺚 | MEDEFAIDRIN EXCLAMATION OH | U+16E9A | Po, other | Medefaidrin | |
| ꫰ | MEETEI MAYEK CHEIKHAN | U+AAF0 | Po, other | Meetei Mayek | |
| ꫱ | MEETEI MAYEK AHANG KHUDAM | U+AAF1 | Po, other | Meetei Mayek | |
| ꯫ | MEETEI MAYEK CHEIKHEI | U+ABEB | Po, other | Meetei Mayek | |
| 𑙁 | MODI DANDA | U+11641 | Po, other | Modi | |
| 𑙂 | MODI DOUBLE DANDA | U+11642 | Po, other | Modi | |
| 𑙃 | MODI ABBREVIATION SIGN | U+11643 | Po, other | Modi | |
| ᠀ | MONGOLIAN BIRGA | U+1800 | Po, other | Mongolian | |
| ᠁ | MONGOLIAN ELLIPSIS | U+1801 | Po, other | Mongolian | |
| ᠄ | MONGOLIAN COLON | U+1804 | Po, other | Mongolian | |
| ᠇ | MONGOLIAN SIBE SYLLABLE BOUNDARY MARKER | U+1807 | Po, other | Mongolian | |
| ᠈ | MONGOLIAN MANCHU COMMA | U+1808 | Po, other | Mongolian | |
| ᠉ | MONGOLIAN MANCHU FULL STOP | U+1809 | Po, other | Mongolian | |
| ᠊ | MONGOLIAN NIRUGU | U+180A | Po, other | Mongolian | |
| 𑙠 | MONGOLIAN BIRGA WITH ORNAMENT | U+11660 | Po, other | Mongolian | |
| 𑙡 | MONGOLIAN ROTATED BIRGA | U+11661 | Po, other | Mongolian | |
| 𑙢 | MONGOLIAN DOUBLE BIRGA WITH ORNAMENT | U+11662 | Po, other | Mongolian | |
| 𑙣 | MONGOLIAN TRIPLE BIRGA WITH ORNAMENT | U+11663 | Po, other | Mongolian | |
| 𑙤 | MONGOLIAN BIRGA WITH DOUBLE ORNAMENT | U+11664 | Po, other | Mongolian | |
| 𑙥 | MONGOLIAN ROTATED BIRGA WITH ORNAMENT | U+11665 | Po, other | Mongolian | |
| 𑙦 | MONGOLIAN ROTATED BIRGA WITH DOUBLE ORNAMENT | U+11666 | Po, other | Mongolian | |
| 𑙧 | MONGOLIAN INVERTED BIRGA | U+11667 | Po, other | Mongolian | |
| 𑙨 | MONGOLIAN INVERTED BIRGA WITH DOUBLE ORNAMENT | U+11668 | Po, other | Mongolian | |
| 𑙩 | MONGOLIAN SWIRL BIRGA | U+11669 | Po, other | Mongolian | |
| 𑙪 | MONGOLIAN SWIRL BIRGA WITH ORNAMENT | U+1166A | Po, other | Mongolian | |
| 𑙫 | MONGOLIAN SWIRL BIRGA WITH DOUBLE ORNAMENT | U+1166B | Po, other | Mongolian | |
| 𑙬 | MONGOLIAN TURNED SWIRL BIRGA WITH DOUBLE ORNAMENT | U+1166C | Po, other | Mongolian | |
| 𖩮 | MRO DANDA | U+16A6E | Po, other | Mro | |
| 𖩯 | MRO DOUBLE DANDA | U+16A6F | Po, other | Mro | |
| 𑊩 | MULTANI SECTION MARK | U+112A9 | Po, other | Multani | |
| ၊ | MYANMAR SIGN LITTLE SECTION | U+104A | Po, other | Myanmar | |
| ။ | MYANMAR SIGN SECTION | U+104B | Po, other | Myanmar | |
| ၌ | MYANMAR SYMBOL LOCATIVE | U+104C | Po, other | Myanmar | |
| ၍ | MYANMAR SYMBOL COMPLETED | U+104D | Po, other | Myanmar | |
| ၎ | MYANMAR SYMBOL AFOREMENTIONED | U+104E | Po, other | Myanmar | |
| ၏ | MYANMAR SYMBOL GENITIVE | U+104F | Po, other | Myanmar | |
| ߷ | NKO SYMBOL GBAKURUNEN | U+07F7 | Po, other | N'Ko | |
| ߸ | NKO COMMA | U+07F8 | Po, other | N'Ko | |
| ߹ | NKO EXCLAMATION MARK | U+07F9 | Po, other | N'Ko | |
| 𑧢 | NANDINAGARI SIGN SIDDHAM | U+119E2 | Po, other | Nandinagari | |
| 𑑋 | NEWA DANDA | U+1144B | Po, other | Newa | |
| 𑑌 | NEWA DOUBLE DANDA | U+1144C | Po, other | Newa | |
| 𑑍 | NEWA COMMA | U+1144D | Po, other | Newa | |
| 𑑎 | NEWA GAP FILLER | U+1144E | Po, other | Newa | |
| 𑑏 | NEWA ABBREVIATION SIGN | U+1144F | Po, other | Newa | |
| 𑑚 | NEWA DOUBLE COMMA | U+1145A | Po, other | Newa | |
| 𑑛 | NEWA PLACEHOLDER MARK | U+1145B | Po, other | Newa | |
| 𑑝 | NEWA INSERTION SIGN | U+1145D | Po, other | Newa | |
| ᱾ | OL CHIKI PUNCTUATION MUCAAD | U+1C7E | Po, other | Ol Chiki | |
| ᱿ | OL CHIKI PUNCTUATION DOUBLE MUCAAD | U+1C7F | Po, other | Ol Chiki | |
| 𐏐 | OLD PERSIAN WORD DIVIDER | U+103D0 | Po, other | Old Persian | |
| 𐩿 | OLD SOUTH ARABIAN NUMERIC INDICATOR | U+10A7F | Po, other | Old South Arabian | |
| 𖬷 | PAHAWH HMONG SIGN VOS THOM | U+16B37 | Po, other | Pahawh Hmong | |
| 𖬸 | PAHAWH HMONG SIGN VOS TSHAB CEEB | U+16B38 | Po, other | Pahawh Hmong | |
| 𖬹 | PAHAWH HMONG SIGN CIM CHEEM | U+16B39 | Po, other | Pahawh Hmong | |
| 𖬺 | PAHAWH HMONG SIGN VOS THIAB | U+16B3A | Po, other | Pahawh Hmong | |
| 𖬻 | PAHAWH HMONG SIGN VOS FEEM | U+16B3B | Po, other | Pahawh Hmong | |
| 𖭄 | PAHAWH HMONG SIGN XAUS | U+16B44 | Po, other | Pahawh Hmong | |
| ꡴ | PHAGS-PA SINGLE HEAD MARK | U+A874 | Po, other | Phags-pa | |
| ꡵ | PHAGS-PA DOUBLE HEAD MARK | U+A875 | Po, other | Phags-pa | |
| ꡶ | PHAGS-PA MARK SHAD | U+A876 | Po, other | Phags-pa | |
| ꡷ | PHAGS-PA MARK DOUBLE SHAD | U+A877 | Po, other | Phags-pa | |
| 𐤟 | PHOENICIAN WORD SEPARATOR | U+1091F | Po, other | Phoenician | |
| 𐮙 | PSALTER PAHLAVI SECTION MARK | U+10B99 | Po, other | Psalter Pahlavi | |
| 𐮚 | PSALTER PAHLAVI TURNED SECTION MARK | U+10B9A | Po, other | Psalter Pahlavi | |
| 𐮛 | PSALTER PAHLAVI FOUR DOTS WITH CROSS | U+10B9B | Po, other | Psalter Pahlavi | |
| 𐮜 | PSALTER PAHLAVI FOUR DOTS WITH DOT | U+10B9C | Po, other | Psalter Pahlavi | |
| ꥟ | REJANG SECTION MARK | U+A95F | Po, other | Rejang | |
| ࠰ | SAMARITAN PUNCTUATION NEQUDAA | U+0830 | Po, other | Samaritan | |
| ࠱ | SAMARITAN PUNCTUATION AFSAAQ | U+0831 | Po, other | Samaritan | |
| ࠲ | SAMARITAN PUNCTUATION ANGED | U+0832 | Po, other | Samaritan | |
| ࠳ | SAMARITAN PUNCTUATION BAU | U+0833 | Po, other | Samaritan | |
| ࠴ | SAMARITAN PUNCTUATION ATMAAU | U+0834 | Po, other | Samaritan | |
| ࠵ | SAMARITAN PUNCTUATION SHIYYAALAA | U+0835 | Po, other | Samaritan | |
| ࠶ | SAMARITAN ABBREVIATION MARK | U+0836 | Po, other | Samaritan | |
| ࠷ | SAMARITAN PUNCTUATION MELODIC QITSA | U+0837 | Po, other | Samaritan | |
| ࠸ | SAMARITAN PUNCTUATION ZIQAA | U+0838 | Po, other | Samaritan | |
| ࠹ | SAMARITAN PUNCTUATION QITSA | U+0839 | Po, other | Samaritan | |
| ࠺ | SAMARITAN PUNCTUATION ZAEF | U+083A | Po, other | Samaritan | |
| ࠻ | SAMARITAN PUNCTUATION TURU | U+083B | Po, other | Samaritan | |
| ࠼ | SAMARITAN PUNCTUATION ARKAANU | U+083C | Po, other | Samaritan | |
| ࠽ | SAMARITAN PUNCTUATION SOF MASHFAAT | U+083D | Po, other | Samaritan | |
| ࠾ | SAMARITAN PUNCTUATION ANNAAU | U+083E | Po, other | Samaritan | |
| ꣎ | SAURASHTRA DANDA | U+A8CE | Po, other | Saurashtra | |
| ꣏ | SAURASHTRA DOUBLE DANDA | U+A8CF | Po, other | Saurashtra | |
| 𑇅 | SHARADA DANDA | U+111C5 | Po, other | Sharada | |
| 𑇆 | SHARADA DOUBLE DANDA | U+111C6 | Po, other | Sharada | |
| 𑇇 | SHARADA ABBREVIATION SIGN | U+111C7 | Po, other | Sharada | |
| 𑇈 | SHARADA SEPARATOR | U+111C8 | Po, other | Sharada | |
| 𑇍 | SHARADA SUTRA MARK | U+111CD | Po, other | Sharada | |
| 𑇛 | SHARADA SIGN SIDDHAM | U+111DB | Po, other | Sharada | |
| 𑇝 | SHARADA CONTINUATION SIGN | U+111DD | Po, other | Sharada | |
| 𑇞 | SHARADA SECTION MARK-1 | U+111DE | Po, other | Sharada | |
| 𑇟 | SHARADA SECTION MARK-2 | U+111DF | Po, other | Sharada | |
| 𑗁 | SIDDHAM SIGN SIDDHAM | U+115C1 | Po, other | Siddham | |
| 𑗂 | SIDDHAM DANDA | U+115C2 | Po, other | Siddham | |
| 𑗃 | SIDDHAM DOUBLE DANDA | U+115C3 | Po, other | Siddham | |
| 𑗄 | SIDDHAM SEPARATOR DOT | U+115C4 | Po, other | Siddham | |
| 𑗅 | SIDDHAM SEPARATOR BAR | U+115C5 | Po, other | Siddham | |
| 𑗆 | SIDDHAM REPETITION MARK-1 | U+115C6 | Po, other | Siddham | |
| 𑗇 | SIDDHAM REPETITION MARK-2 | U+115C7 | Po, other | Siddham | |
| 𑗈 | SIDDHAM REPETITION MARK-3 | U+115C8 | Po, other | Siddham | |
| 𑗉 | SIDDHAM END OF TEXT MARK | U+115C9 | Po, other | Siddham | |
| 𑗊 | SIDDHAM SECTION MARK WITH TRIDENT AND U-SHAPED ORNAMENTS | U+115CA | Po, other | Siddham | |
| 𑗋 | SIDDHAM SECTION MARK WITH TRIDENT AND DOTTED CRESCENTS | U+115CB | Po, other | Siddham | |
| 𑗌 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED CRESCENTS | U+115CC | Po, other | Siddham | |
| 𑗍 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED DOUBLE CRESCENTS | U+115CD | Po, other | Siddham | |
| 𑗎 | SIDDHAM SECTION MARK WITH RAYS AND DOTTED TRIPLE CRESCENTS | U+115CE | Po, other | Siddham | |
| 𑗏 | SIDDHAM SECTION MARK DOUBLE RING | U+115CF | Po, other | Siddham | |
| 𑗐 | SIDDHAM SECTION MARK DOUBLE RING WITH RAYS | U+115D0 | Po, other | Siddham | |
| 𑗑 | SIDDHAM SECTION MARK WITH DOUBLE CRESCENTS | U+115D1 | Po, other | Siddham | |
| 𑗒 | SIDDHAM SECTION MARK WITH TRIPLE CRESCENTS | U+115D2 | Po, other | Siddham | |
| 𑗓 | SIDDHAM SECTION MARK WITH QUADRUPLE CRESCENTS | U+115D3 | Po, other | Siddham | |
| 𑗔 | SIDDHAM SECTION MARK WITH SEPTUPLE CRESCENTS | U+115D4 | Po, other | Siddham | |
| 𑗕 | SIDDHAM SECTION MARK WITH CIRCLES AND RAYS | U+115D5 | Po, other | Siddham | |
| 𑗖 | SIDDHAM SECTION MARK WITH CIRCLES AND TWO ENCLOSURES | U+115D6 | Po, other | Siddham | |
| 𑗗 | SIDDHAM SECTION MARK WITH CIRCLES AND FOUR ENCLOSURES | U+115D7 | Po, other | Siddham | |
| 𝪇 | SIGNWRITING COMMA | U+1DA87 | Po, other | SignWriting | |
| 𝪈 | SIGNWRITING FULL STOP | U+1DA88 | Po, other | SignWriting | |
| 𝪉 | SIGNWRITING SEMICOLON | U+1DA89 | Po, other | SignWriting | |
| 𝪊 | SIGNWRITING COLON | U+1DA8A | Po, other | SignWriting | |
| 𝪋 | SIGNWRITING PARENTHESIS | U+1DA8B | Po, other | SignWriting | |
| ෴ | SINHALA PUNCTUATION KUNDDALIYA | U+0DF4 | Po, other | Sinhala | |
| 𐽕 | SOGDIAN PUNCTUATION TWO VERTICAL BARS | U+10F55 | Po, other | Sogdian | |
| 𐽖 | SOGDIAN PUNCTUATION TWO VERTICAL BARS WITH DOTS | U+10F56 | Po, other | Sogdian | |
| 𐽗 | SOGDIAN PUNCTUATION CIRCLE WITH DOT | U+10F57 | Po, other | Sogdian | |
| 𐽘 | SOGDIAN PUNCTUATION TWO CIRCLES WITH DOTS | U+10F58 | Po, other | Sogdian | |
| 𐽙 | SOGDIAN PUNCTUATION HALF CIRCLE WITH DOT | U+10F59 | Po, other | Sogdian | |
| 𑪚 | SOYOMBO MARK TSHEG | U+11A9A | Po, other | Soyombo | |
| 𑪛 | SOYOMBO MARK SHAD | U+11A9B | Po, other | Soyombo | |
| 𑪜 | SOYOMBO MARK DOUBLE SHAD | U+11A9C | Po, other | Soyombo | |
| 𑪞 | SOYOMBO HEAD MARK WITH MOON AND SUN AND TRIPLE FLAME | U+11A9E | Po, other | Soyombo | |
| 𑪟 | SOYOMBO HEAD MARK WITH MOON AND SUN AND FLAME | U+11A9F | Po, other | Soyombo | |
| 𑪠 | SOYOMBO HEAD MARK WITH MOON AND SUN | U+11AA0 | Po, other | Soyombo | |
| 𑪡 | SOYOMBO TERMINAL MARK-1 | U+11AA1 | Po, other | Soyombo | |
| 𑪢 | SOYOMBO TERMINAL MARK-2 | U+11AA2 | Po, other | Soyombo | |
| ᳀ | SUNDANESE PUNCTUATION BINDU SURYA | U+1CC0 | Po, other | Sundanese | |
| ᳁ | SUNDANESE PUNCTUATION BINDU PANGLONG | U+1CC1 | Po, other | Sundanese | |
| ᳂ | SUNDANESE PUNCTUATION BINDU PURNAMA | U+1CC2 | Po, other | Sundanese | |
| ᳃ | SUNDANESE PUNCTUATION BINDU CAKRA | U+1CC3 | Po, other | Sundanese | |
| ᳄ | SUNDANESE PUNCTUATION BINDU LEU SATANGA | U+1CC4 | Po, other | Sundanese | |
| ᳅ | SUNDANESE PUNCTUATION BINDU KA SATANGA | U+1CC5 | Po, other | Sundanese | |
| ᳆ | SUNDANESE PUNCTUATION BINDU DA SATANGA | U+1CC6 | Po, other | Sundanese | |
| ᳇ | SUNDANESE PUNCTUATION BINDU BA SATANGA | U+1CC7 | Po, other | Sundanese | |
| ܀ | SYRIAC END OF PARAGRAPH | U+0700 | Po, other | Syriac | |
| ܁ | SYRIAC SUPRALINEAR FULL STOP | U+0701 | Po, other | Syriac | |
| ܂ | SYRIAC SUBLINEAR FULL STOP | U+0702 | Po, other | Syriac | |
| ܃ | SYRIAC SUPRALINEAR COLON | U+0703 | Po, other | Syriac | |
| ܄ | SYRIAC SUBLINEAR COLON | U+0704 | Po, other | Syriac | |
| ܅ | SYRIAC HORIZONTAL COLON | U+0705 | Po, other | Syriac | |
| ܆ | SYRIAC COLON SKEWED LEFT | U+0706 | Po, other | Syriac | |
| ܇ | SYRIAC COLON SKEWED RIGHT | U+0707 | Po, other | Syriac | |
| ܈ | SYRIAC SUPRALINEAR COLON SKEWED LEFT | U+0708 | Po, other | Syriac | |
| ܉ | SYRIAC SUBLINEAR COLON SKEWED RIGHT | U+0709 | Po, other | Syriac | |
| ܊ | SYRIAC CONTRACTION | U+070A | Po, other | Syriac | |
| ܋ | SYRIAC HARKLEAN OBELUS | U+070B | Po, other | Syriac | |
| ܌ | SYRIAC HARKLEAN METOBELUS | U+070C | Po, other | Syriac | |
| ܍ | SYRIAC HARKLEAN ASTERISCUS | U+070D | Po, other | Syriac | |
| ᪠ | TAI THAM SIGN WIANG | U+1AA0 | Po, other | Tai Tham | |
| ᪡ | TAI THAM SIGN WIANGWAAK | U+1AA1 | Po, other | Tai Tham | |
| ᪢ | TAI THAM SIGN SAWAN | U+1AA2 | Po, other | Tai Tham | |
| ᪣ | TAI THAM SIGN KEOW | U+1AA3 | Po, other | Tai Tham | |
| ᪤ | TAI THAM SIGN HOY | U+1AA4 | Po, other | Tai Tham | |
| ᪥ | TAI THAM SIGN DOKMAI | U+1AA5 | Po, other | Tai Tham | |
| ᪦ | TAI THAM SIGN REVERSED ROTATED RANA | U+1AA6 | Po, other | Tai Tham | |
| ᪨ | TAI THAM SIGN KAAN | U+1AA8 | Po, other | Tai Tham | |
| ᪩ | TAI THAM SIGN KAANKUU | U+1AA9 | Po, other | Tai Tham | |
| ᪪ | TAI THAM SIGN SATKAAN | U+1AAA | Po, other | Tai Tham | |
| ᪫ | TAI THAM SIGN SATKAANKUU | U+1AAB | Po, other | Tai Tham | |
| ᪬ | TAI THAM SIGN HANG | U+1AAC | Po, other | Tai Tham | |
| ᪭ | TAI THAM SIGN CAANG | U+1AAD | Po, other | Tai Tham | |
| ꫞ | TAI VIET SYMBOL HO HOI | U+AADE | Po, other | Tai Viet | |
| ꫟ | TAI VIET SYMBOL KOI KOI | U+AADF | Po, other | Tai Viet | |
| 𑿿 | TAMIL PUNCTUATION END OF TEXT | U+11FFF | Po, other | Tamil | |
| ౷ | TELUGU SIGN SIDDHAM | U+0C77 | Po, other | Telugu | |
| ๏ | THAI CHARACTER FONGMAN | U+0E4F | Po, other | Thai | |
| ๚ | THAI CHARACTER ANGKHANKHU | U+0E5A | Po, other | Thai | |
| ๛ | THAI CHARACTER KHOMUT | U+0E5B | Po, other | Thai | |
| ༄ | TIBETAN MARK INITIAL YIG MGO MDUN MA | U+0F04 | Po, other | Tibetan | |
| ༅ | TIBETAN MARK CLOSING YIG MGO SGAB MA | U+0F05 | Po, other | Tibetan | |
| ༆ | TIBETAN MARK CARET YIG MGO PHUR SHAD MA | U+0F06 | Po, other | Tibetan | |
| ༇ | TIBETAN MARK YIG MGO TSHEG SHAD MA | U+0F07 | Po, other | Tibetan | |
| ༈ | TIBETAN MARK SBRUL SHAD | U+0F08 | Po, other | Tibetan | |
| ༉ | TIBETAN MARK BSKUR YIG MGO | U+0F09 | Po, other | Tibetan | |
| ༊ | TIBETAN MARK BKA- SHOG YIG MGO | U+0F0A | Po, other | Tibetan | |
| ་ | TIBETAN MARK INTERSYLLABIC TSHEG | U+0F0B | Po, other | Tibetan | |
| ༌ | TIBETAN MARK DELIMITER TSHEG BSTAR | U+0F0C | Po, other | Tibetan | |
| ། | TIBETAN MARK SHAD | U+0F0D | Po, other | Tibetan | |
| ༎ | TIBETAN MARK NYIS SHAD | U+0F0E | Po, other | Tibetan | |
| ༏ | TIBETAN MARK TSHEG SHAD | U+0F0F | Po, other | Tibetan | |
| ༐ | TIBETAN MARK NYIS TSHEG SHAD | U+0F10 | Po, other | Tibetan | |
| ༑ | TIBETAN MARK RIN CHEN SPUNGS SHAD | U+0F11 | Po, other | Tibetan | |
| ༒ | TIBETAN MARK RGYA GRAM SHAD | U+0F12 | Po, other | Tibetan | |
| ༔ | TIBETAN MARK GTER TSHEG | U+0F14 | Po, other | Tibetan | |
| ྅ | TIBETAN MARK PALUTA | U+0F85 | Po, other | Tibetan | |
| ࿐ | TIBETAN MARK BSKA- SHOG GI MGO RGYAN | U+0FD0 | Po, other | Tibetan | |
| ࿑ | TIBETAN MARK MNYAM YIG GI MGO RGYAN | U+0FD1 | Po, other | Tibetan | |
| ࿒ | TIBETAN MARK NYIS TSHEG | U+0FD2 | Po, other | Tibetan | |
| ࿓ | TIBETAN MARK INITIAL BRDA RNYING YIG MGO MDUN MA | U+0FD3 | Po, other | Tibetan | |
| ࿔ | TIBETAN MARK CLOSING BRDA RNYING YIG MGO SGAB MA | U+0FD4 | Po, other | Tibetan | |
| ࿙ | TIBETAN MARK LEADING MCHAN RTAGS | U+0FD9 | Po, other | Tibetan | |
| ࿚ | TIBETAN MARK TRAILING MCHAN RTAGS | U+0FDA | Po, other | Tibetan | |
| ⵰ | TIFINAGH SEPARATOR MARK | U+2D70 | Po, other | Tifinagh | |
| 𑓆 | TIRHUTA ABBREVIATION SIGN | U+114C6 | Po, other | Tirhuta | |
| 𐎟 | UGARITIC WORD DIVIDER | U+1039F | Po, other | Ugaritic | |
| ꘍ | VAI COMMA | U+A60D | Po, other | Vai | |
| ꘎ | VAI FULL STOP | U+A60E | Po, other | Vai | |
| ꘏ | VAI QUESTION MARK | U+A60F | Po, other | Vai | |
| 𑨿 | ZANABAZAR SQUARE INITIAL HEAD MARK | U+11A3F | Po, other | Zanabazar Square | |
| 𑩀 | ZANABAZAR SQUARE CLOSING HEAD MARK | U+11A40 | Po, other | Zanabazar Square | |
| 𑩁 | ZANABAZAR SQUARE MARK TSHEG | U+11A41 | Po, other | Zanabazar Square | |
| 𑩂 | ZANABAZAR SQUARE MARK SHAD | U+11A42 | Po, other | Zanabazar Square | |
| 𑩃 | ZANABAZAR SQUARE MARK DOUBLE SHAD | U+11A43 | Po, other | Zanabazar Square | |
| 𑩄 | ZANABAZAR SQUARE MARK LONG TSHEG | U+11A44 | Po, other | Zanabazar Square | |
| 𑩅 | ZANABAZAR SQUARE INITIAL DOUBLE-LINED HEAD MARK | U+11A45 | Po, other | Zanabazar Square | |
| 𑩆 | ZANABAZAR SQUARE CLOSING DOUBLE-LINED HEAD MARK | U+11A46 | Po, other | Zanabazar Square | |
| ࡞ | MANDAIC PUNCTUATION | U+085E | Po, other | Mandaic | |
See also
- Diacritic
- James while John had had had had had had had had had had had a better effect on the teacher, a word puzzle
- Obelism, the practice of annotating manuscripts with marks set in the margins
- Orthography, the category of written conventions that includes punctuation as well as spelling, hyphenation, capitalization, word breaks, and emphasis
- Scribal abbreviations, abbreviations used by ancient and medieval scribes writing in Latin
- Terminal punctuation
- History of sentence spacing for typographical details
- Tironian notes, a system of shorthand that consisted of about 4,000 signs
- Usage
Notes
- ^ The Latin names for the marks are subdistinctio, media distinctio, and distinctio.
References
Citations
- ^ Encyclopædia Britannica: "Punctuation.
- ^ Byrne, Eugene. "Q&A: When were punctuation marks first used?". History Extra. BBC. Retrieved 14 February 2017.
- ^ Truss, Lynn (2004). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. New York: Gotham Books. p. 112. ISBN 1-59240-087-6.
- ^ Bazin, Hervé (1966), Plumons l'oiseau, Paris (France): Éditions Bernard Grasset, p. 142
- ^ Truss, Lynne (2003). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. Profile Books. ISBN 1-86197-612-7.
- ^ 林清源,《簡牘帛書標題格式研究》台北: 藝文印書館,2006。(Lin Qingyuan, Study of Title Formatting in Bamboo and Silk Texts Taipei: Yiwen Publishing, 2006.) ISBN 957-520-111-6.
- ^ The History of the Song Dynasty (1346) states 「凡所讀書,無不加標點。」 (Among those who read texts, there are none who do not add punctuation).
- ^ E. Otha Wingo, Latin Punctuation in the Classical Age (The Hague, Netherlands: De Gruyter, 1972), 22.
- ^ Parkes, M. B. (1991). "The Contribution of Insular Scribes of the Seventh and Eighth Centuries to the 'Grammar of Legibility'". Scribes, Scripts and Readers: Studies in the Communication, Presentation and Dissemination of Medieval Texts. London: Hambledon Press. pp. 1–18.
- ^ "Paleography: How to Read Medieval Handwriting". Harvard University. Archived from the original on 8 December 2015. Retrieved 13 November 2017.
- ^ Raymond Clemens & Timothy Graham, Introduction to Manuscript Studies (Ithaca–London: Cornell UP, 2007), 84–6.
- ^ Historische Kommasetzung bei Luther, en: historical use of comma by Luther, Frank Slotta, for Prof Beatrice Primus, Landesprüfungsamt I NRW, 2010.
- ^ Truss, Lynne (2004). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. New York: Gotham Books. p. 77. ISBN 1-59240-087-6.
- ^ Truss, Lynn (2004). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. New York: Gotham Books. pp. 77–78. ISBN 1-59240-087-6.
- ^ Truss, Lynn (2004). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. New York: Gotham Books. p. 112. ISBN 1-59240-087-6.
- ^ Truss, Lynn (2004). Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation. New York: Gotham Books. pp. 112–113. ISBN 1-59240-087-6.
- ^ Iona and Peter Opie (1943) I Saw Esau.
- ^ MacKellar, Thomas (1885). The American Printer: A Manual of Typography, Containing Practical Directions for Managing all Departments of a Printing Office, As Well as Complete Instructions for Apprentices: With Several Useful Tables, Numerous Schemes for Imposing Forms in Every Variety, Hints to Authors, Etc (Fifteenth – Revised and Enlarged ed.). Philadelphia: MacKellar, Smiths & Jordan. p. 63.
- ^ See e.g. Morse code
- ^ Chelsea, Lee. "Punctuating Around Quotation Marks". APA Style. American Psychological Association. Retrieved 16 February 2017.
- ^ Bryan, Chloe (12 March 2019). "Why people leave a space before punctuation in texts". Mashable. Retrieved 10 June 2022.
- ^ Tetteroo, Jeroen (19 August 2015). "Designer's Style Guide to French Translation for Canada". LanguageSolutions. Retrieved 10 June 2022.
- ^ Put, Olga (26 February 2022). "What Is the Upside-Down Question Mark in Spanish?". Spanish Academy. Retrieved 10 June 2022.
- ^ "Punctuation in Different Languages". TranslateMedia. 11 July 2013. Retrieved 10 June 2022.
- ^ Prasoon, Shrikant (2015). English Grammar and Usage. New Delhi: V & S Publishers. pp. Chapter 6. ISBN 978-93-505742-6-3.
- ^ Haley, Allan (June 2001). "The Interrobang Is Back". fonthaus.com. Archived from the original on 7 May 2008. Retrieved 3 December 2010.
- ^ Bazin, Hervé (1966), Plumons l'oiseau, Paris (France): Éditions Bernard Grasset, p. 142
- ^ Revised preliminary proposal to encode six punctuation characters introduced by Hervé Bazin in the UCS by Mykyta Yevstifeyev and Karl Pentzlin, 28 Feb. 2012
- ^ "European Patent Office publication".
- ^ Australian Official Journal of Patents, 27 January 1994
- ^ CIPO – Patent – 2102803 – Financial Transactions Archived 2 October 2008 at the Wayback Machine
- ^ Brandon Specktor; Samantha Rideout (20 March 2019). "11 Little-Known Punctuation Marks We Should Be Using". Reader's Digest Canada.
Further reading
- Allen, Robert (25 July 2002). Punctuation. Oxford University Press. ISBN 0-19-860439-4.
- Amis, Kingsley (2 March 1998). The King's English: A Guide to Modern Usage. HarperCollins. ISBN 0-00-638746-2.
- Fowler, Henry Watson; Francis George Fowler (June 2002) [1906]. The King's English. Oxford University Press. ISBN 0-19-860507-2.
- Gowers, Ernest (1948). Plain Words: a guide to the use of English. London: Her Majesty's Stationery Office.
- Houston, Keith (2013). Shady Characters: Ampersands, Interrobangs and other Typographical Curiosities. Particular.
- Parkes, Malcolm Beckwith (1993). Pause and Effect: An Introduction to the History of Punctuation in the West. University of California Press. ISBN 0-520-07941-8.
- Patt, Sebastian (2013). Punctuation as a Means of Medium-Dependent Presentation Structure in English: Exploring the Guide Functions of Punctuation. Tübingen: Narr Francke Attempto Verlag. ISBN 978-3-8233-6753-6.
External links
- Larry Trask: Guide to Punctuation – a helpful online resource
- History of Punctuation (in French) – helpful photographs of early punctuation
- Punctuation Marks in English: Clarity in Expression
- Unicode reference tables:
- Unicode collation charts—including punctuation marks, sorted by shape
- "General punctuation U2000" (PDF).
- "CJK Symbols and Punctuation U3000" (PDF).
- "CJK Compatibility Forms UFE30" (PDF).
- "Small Form Variants UFE50" (PDF).
- "Halfwidth and Fullwidth Forms UFF00" (PDF).
- Ethiopic script
- Automatic Recovery of Capitalization and Punctuation of Automatic Speech Transcripts
- English Punctuation Rules
- Punctuation marks with independent clauses, by Jennifer Frost
| Page | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Paragraph | |||||||||||
| Character |
| ||||||||||
| Typeface classifications |
| ||||||||||
| Punctuation (List) | |||||||||||
| Typesetting | |||||||||||
| Typographic units | |||||||||||
| Digital typography | |||||||||||
| Typography in other writing systems | |||||||||||
| Related articles | |||||||||||
| Related template | |||||||||||