
Search results
The page "Spectral function, estimator of the" does not exist. You can create a draft and submit it for review or request that a redirect be created, but consider checking the search results below to see whether the topic is already covered.
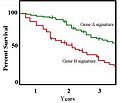 The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime...27 KB (4,458 words) - 16:02, 11 November 2024
The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime...27 KB (4,458 words) - 16:02, 11 November 2024- the goal of spectral density estimation (SDE) or simply spectral estimation is to estimate the spectral density (also known as the power spectral density)...23 KB (3,535 words) - 13:19, 8 November 2024
- a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function (i.e., the posterior...22 KB (3,845 words) - 16:15, 22 August 2024
- In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares...22 KB (2,854 words) - 17:15, 5 November 2024
- Maximum likelihood estimation (redirect from Maximum likelihood estimator)uniform in the region of interest. In frequentist inference, MLE is a special case of an extremum estimator, with the objective function being the likelihood...67 KB (9,702 words) - 15:07, 28 November 2024
- minimum-variance unbiased estimator (MVUE) or uniformly minimum-variance unbiased estimator (UMVUE) is an unbiased estimator that has lower variance than...7 KB (1,107 words) - 11:26, 21 May 2023
- but includes vector valued or function valued estimators. Estimation theory is concerned with the properties of estimators; that is, with defining properties...25 KB (3,709 words) - 12:57, 5 January 2025
 median is the estimator that minimizes expected loss experienced under the absolute-difference loss function. Still different estimators would be optimal...21 KB (2,798 words) - 18:54, 1 January 2025
median is the estimator that minimizes expected loss experienced under the absolute-difference loss function. Still different estimators would be optimal...21 KB (2,798 words) - 18:54, 1 January 2025 Median (redirect from Median unbiased estimator)the medians of the subsamples. Any mean-unbiased estimator minimizes the risk (expected loss) with respect to the squared-error loss function, as observed...62 KB (7,974 words) - 14:03, 22 November 2024
Median (redirect from Median unbiased estimator)the medians of the subsamples. Any mean-unbiased estimator minimizes the risk (expected loss) with respect to the squared-error loss function, as observed...62 KB (7,974 words) - 14:03, 22 November 2024- Robust statistics (redirect from Robust estimator)outliers in the data, classical estimators often have very poor performance, when judged using the breakdown point and the influence function described...46 KB (6,367 words) - 05:03, 22 November 2024
- statistics, the bias of an estimator (or bias function) is the difference between this estimator's expected value and the true value of the parameter being...34 KB (5,359 words) - 21:46, 1 November 2024
- Estimation theory (redirect from Statistical estimator)their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation...17 KB (2,555 words) - 10:23, 26 November 2024
- Rao–Blackwell theorem (redirect from Rao-Blackwell estimator)arbitrarily crude estimator into an estimator that is optimal by the mean-squared-error criterion or any of a variety of similar criteria. The Rao–Blackwell...13 KB (2,164 words) - 15:10, 19 November 2023
- In that sense, the maximum likelihood estimator is implicitly defined by the value at 0 {\textstyle \mathbf {0} } of the inverse function s n − 1 : E d...64 KB (8,544 words) - 05:19, 13 December 2024
- Completeness (statistics) (redirect from Unbiased estimator of zero)mean-unbiased estimator for θ. In other words, this statistic has a smaller expected loss for any convex loss function; in many practical applications with the squared...12 KB (1,731 words) - 11:36, 13 December 2024
 distribution function (commonly also called an empirical cumulative distribution function, eCDF) is the distribution function associated with the empirical...13 KB (1,514 words) - 13:44, 4 September 2024
distribution function (commonly also called an empirical cumulative distribution function, eCDF) is the distribution function associated with the empirical...13 KB (1,514 words) - 13:44, 4 September 2024- estimator – redirects to Maximum a posteriori estimation Marchenko–Pastur distribution Marcinkiewicz–Zygmund inequality Marcum Q-function Margin of error...87 KB (8,285 words) - 04:29, 7 October 2024
- Maximum a posteriori estimation (redirect from MAP estimator)of typical loss functions—and for a continuous posterior distribution there is no loss function which suggests the MAP is the optimal point estimator...11 KB (1,725 words) - 05:26, 19 December 2024
- Efficiency (statistics) (redirect from Efficiency of estimators)measure of quality of an estimator, of an experimental design, or of a hypothesis testing procedure. Essentially, a more efficient estimator needs fewer...22 KB (3,066 words) - 12:19, 4 December 2024
- Resampling (statistics) (redirect from Jackknife estimator)estimating the sampling distribution of an estimator by sampling with replacement from the original sample, most often with the purpose of deriving robust...18 KB (2,225 words) - 15:27, 31 July 2024
- moment generating function, random sums of random variables. 3. MMSE estimation: blind, linear, unconstraint MMSE estimators, the Gaussian case, orthogonality