Geosemantik
Geosemantik (im Englischen ist der Begriff geospatial semantics üblich) ist ein interdisziplinäres Forschungsfeld und befasst sich mit der Bedeutung von Geoinformation.

Grundlagen
[Bearbeiten | Quelltext bearbeiten]Faktoren wie der gewünschte Anwendungszweck oder Kenntnisse des Urhebers beeinflussen die Interpretation räumlicher Daten. Integration über die Grenzen verschiedener Fachgebiete und Anwendungen hinaus erfordert, dass voneinander abweichende Interpretationen ausgeschlossen werden können. Dies kann unter anderem mit expliziten Beschreibungen der Bedeutung (der Semantik) erreicht werden. Die Entwicklung von Strategien, rechnerischen Methoden und Werkzeugen zum Erreichen dieser semantischen Interoperabilität sind Ziele der Geosemantik. Langfristige Ziele sind unter anderem die Verbesserung der Nutzbarkeit und Methoden der Wiedergewinnung von Geoinformation. Geosemantik baut auf Erkenntnissen aus der Geoinformatik, Geographie, Philosophie, Kognitionswissenschaft, Linguistik, Mathematik und Informatik auf.
Al Gores Vision eines virtuellen Globus beschreibt die nahtlose Integration von Geoinformation, wie digitalen Karten, historischen Dokumenten und touristischen Sehenswürdigkeiten, mit Hilfe eines virtuellen Globus. Indem man diese Daten in Zusammenhang bringt, können beispielsweise Themen wie der Klimawandel visualisiert und auch dem Laien verständlich gemacht werden. Dazu ist jedoch ein nahtloses Zusammenspiel von Daten unterschiedlichster Herkunft und Qualität nötig. Indem die Geosemantik verschiedene Sichtweisen auf die Welt explizit macht und Methoden zu deren Integration und Übersetzung entwickelt, baut sie Brücken zwischen verschiedenen Domänen.
Missverständnisquellen
[Bearbeiten | Quelltext bearbeiten]
Sachverhalte über die Umgebung zu kommunizieren führt häufig zu Missverständnissen. Abhängig von Beruf, kulturellem Hintergrund, Sprache, Glauben, Alter und Zweck kann die gleiche Umgebung sehr unterschiedlich verstanden und beschrieben werden. Eine Straße kann aus unterschiedlichen Blickwinkeln betrachtet werden: für einen Straßenbauer erhöht die Straße als Verbindung zwischen Städten die Mobilität der Bevölkerung; für einen Ökologen ist sie eher ein Hindernis für Tiere, welches Naturschutzgebiete zerschneidet. Daraus ergeben sich unterschiedliche Sichtweisen auf die Umwelt.
Ein besonderes semantisches Problem tritt bei der Integration von Geodaten aus verschiedenen Quellen auf. Sowohl Schienen- als auch Straßennetze können als Verkehrsnetze aufgefasst werden. Fehlt eine semantische Beschreibung, können die beiden Datensätze zwar kombiniert werden, eine Routenplanung für Autos liefert dann allerdings unbrauchbare Ergebnisse. Da Geodaten die Grundlage für zahlreiche wichtige Entscheidungen bilden, muss bei der Nutzung dieser Daten die ursprüngliche Bedeutung der Information erhalten bleiben. Nachhaltige Verkehrsplanung erfordert, dass Daten nicht nur über Verkehr und Ökologie, sondern zum Beispiel auch über die Demografie oder Landnutzung berücksichtigt und erfolgreich integriert werden.
Bei der Integration von Daten aus verschiedenen Quellen in eine gemeinsame Anwendung muss die Heterogenität auf allen Ebenen bedacht werden. Unterschiede in der Syntax lassen sich auf diverse Dateiformate und Kodierungen zurückführen. Semantische Konflikte sind durch verschiedene Auffassungen eines Wissensgebietes, unterschiedliches Verständnis des gleichen Begriffes oder einen abweichenden Fokus bei der Datenerfassung zu begründen. Das abgebildete Ortsschild von New Cuyama zeigt den potentiellen Effekt fehlender semantischer Interoperabilität. Drei Zahlen wurden mathematisch korrekt addiert – syntaktische Interoperabilität wird in diesem Fall durch das formal definierte Zahlensystem gewährleistet. Die eigentliche Bedeutung (Bevölkerungszahl, Höhe über Meeresspiegel und Gründungsjahr) dieser drei Zahlen verbietet jedoch eine Summierung.
Semantische Interoperabilität bezieht sich hauptsächlich auf thematische Aspekte räumlicher Daten. Hier fehlt es an einem für Übersetzungen nötigen formalen Referenzsystem wie bei der räumlichen und zeitlichen Dimension. Darüber hinaus gibt es keine Lingua Franca oder ein wie in der Medizin übliches gemeinsames Vokabular. Voraussetzung für korrektes Verständnis sind daher explizite und eindeutige Spezifikationen der Semantik.
Auf Grundlage expliziter und maschinenlesbarer Beschreibungen bietet Geosemantik bei den oben genannten Problemen einen Ansatz. Basierend auf diesen Beschreibungen können Software-Agenten Gemeinsamkeiten und Unterschiede verschiedener Perspektiven identifizieren und Lösungswege zur Sicherstellung der semantischen Interoperabilität bereitstellen. In einer dienstorientierten Architektur ist syntaktische Interoperabilität eine unverzichtbare Voraussetzung für den nahtlosen Austausch von Daten zwischen Diensten. Methoden der Geosemantik können dann eine korrekte, vom Datenlieferanten gewünschte Interpretation einer Suchanfrage des Datenempfängers ermöglichen.
… und mögliche Auswirkungen
[Bearbeiten | Quelltext bearbeiten]Geosemantische Probleme führen häufig zu kleineren und größeren Schwierigkeiten bei Fachleuten und Laien. Diese sind vermeidbar, wenn Anbieter geographischer Informationen beschreiben können, was gemeint ist, und Anwender diese Beschreibungen auswerten können.
- Wo liegt Sydney?
- Dass Ortsnamen selten eindeutig sind, mussten mehrere Reisende erfahren, als sie statt in Australien in Kanada landeten.[1] Das Buchungssystem der Fluggesellschaft hatte die Mehrdeutigkeit von „Sydney“ bei der Flugplanung nicht erkannt.
- Was bedeutet Distanz?
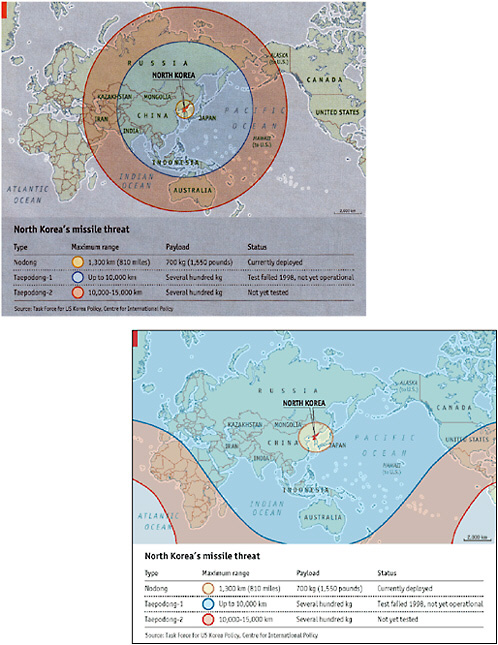
- Am 3. Mai 2003 stellte die renommierte Zeitschrift The Economist die Reichweiten nordkoreanischer Raketen durch konzentrische Kreise auf einer Weltkarte dar, die zudem viel zu klein waren. In der verwendeten Kartenprojektion sind aber Linien gleichen Abstands von einem Punkt auf der Erde keine Kreise, sondern kompliziertere Kurven. In einer korrigierten Karte, die der Economist zwei Wochen später unter der Überschrift „Flat-earth thinking“ publizierte, befanden sich ganze Kontinente, die vorher außerhalb der Reichweite der Langstreckenraketen lagen (Afrika, Europa, Nordamerika), plötzlich innerhalb.[Siehe Abbildung 1]
- Was bedeuten Maßeinheiten?
- Die Marssonde Climate Orbiter bog 1999 in eine zu niedrige Umlaufbahn um dem Planeten ein und verglühte dort, weil ein beteiligtes Unternehmen den Zahlenwert für ein Bremsmanöver, der in der metrischen Einheit Newton-Sekunden angegeben war, in Pfund-Sekunden interpretierte.
- Der griechische Mathematiker, Geograph und Astronom Eratosthenes verbesserte die Messung des Erdumfangs außerordentlich. Er drückte sein Ergebnis allerdings in der Längeneinheit Stadien aus. Da es in der Antike aber mehrere Einheiten dieses Namens gab, bleibt die Genauigkeit seiner Messung ungewiss.
- Was bedeutet Straßenbreite?
- Manche Straßendatensammlungen definieren Straßenbreite als Breite der Fahrbahn, andere als Breite des Lichtraumprofils. Bei der Berechnung von versiegelten Flächen oder von Routen für Schwertransporte mit Überbreite führen solche Abweichungen zu erheblichen Unterschieden.
- Was ist eine Unterkunft?
- Bei der einfachen Anfrage „finde alle Unterkünfte in Amsterdam“ an eine Suchmaschine wie Google muss geklärt werden, was mit „Unterkunft“ gemeint ist: gehören z. B. ein Botel oder ein Zeltplatz mit Bungalows dazu? Je nach verwendeter Interpretation kann das Suchergebnis sehr unterschiedlich ausfallen oder zu unvollständigen Ergebnissen führen.
Anwendungsgebiete
[Bearbeiten | Quelltext bearbeiten]Die Lösung geosemantischer Probleme spielt eine Rolle in vielen Anwendungen. Diese reichen von Geoinformations- und Navigationssystemen über virtuelle Globen und Geodateninfrastrukturen bis hin zu Sensornetzen. Diese Anwendungen lassen sich nach der Art der vorkommenden semantischen Probleme grob in vier Bereiche einteilen: Semantische Interoperabilität und Integration, Semantik-basierte Suche nach Geoinformation, Nutzbarkeit und Prüfung der Datenintegrität.
Semantische Interoperabilität und Integration
[Bearbeiten | Quelltext bearbeiten]

Web-Dienste und andere Softwarekomponenten müssen Information verwenden und weitergeben können, ohne zu Missverständnissen zu führen. Es gilt zwei grundlegende Typen solcher Interoperabilität zu unterscheiden – die syntaktische und semantische Interoperabilität. So können sich zwei Dienste darüber einigen, dass sie ihre Daten in einem bestimmten Format beschreiben. Jedoch kann diese syntaktische Übereinkunft nicht verhindern, dass ein Dienst die Daten des anderen unterschiedlich interpretiert. Zum Beispiel kann ein Datenanbieter eine Verkehrsverbindung als Straße klassifizieren, solange sie eine minimale Breite aufweist, während für eine bestimmte Anfrage der Straßenbelag kritisch sein kann. Solch fehlende semantische Interoperabilität kann dazu führen, dass Touristenbusse im Schlamm stecken bleiben.
Web-Dienste finden und zusammenfügen
[Bearbeiten | Quelltext bearbeiten]Um Web-Dienste automatisch auffinden und zusammenfügen zu können, müssen diese semantisch beschrieben werden. Ein Beispiel für eine Implementierung semantischer Dienste ist das europäische Forschungsprojekt SWING (Semantic Web-service Interoperability for Geospatial decision making).[2] Es hatte das Ziel, Web-Dienste semantisch so zu annotieren, dass sie sinnvoll kombiniert und zur Verarbeitung geographischer Objekte (z. B. Lagerstätten) verwendet werden können. Dazu war eine Einigung über ein gemeinsames semantisches Modell der Anwendung in Form einer Anwendungsontologie notwendig (siehe Abschnitt Konstruktion formaler Theorien über die Umwelt), an deren Entwicklung sich Anwendungsexperten beteiligten. Treffen zwischen diesen Experten und Ontologie-Ingenieuren erlaubten es, inhaltliche Anliegen der Anwender zu berücksichtigen, ohne dass diese sich in den Datenquellen oder Verarbeitungsmechanismen auszukennen brauchten.
Semantisches Sensor-Web
[Bearbeiten | Quelltext bearbeiten]Das Semantische Sensor-Web[3] ist ein neues Forschungsthema der Geosemantik. Es befasst sich mit der halbautomatischen Integration von Sensoren und Sensordaten in Geodateninfrastrukturen. Dabei werden Ergebnisse aus dem Sensor Web Enablement (SWE) mit den Möglichkeiten des Semantischen Web kombiniert. Das Ziel des Semantischen Sensor-Web ist, Beobachtungsergebnisse im Internet zugänglich zu machen, anstatt sie in Daten-Silos zu isolieren. Damit will man den Wissenschaftlern ein besseres Verständnis von Umweltphänomenen ermöglichen. Langfristig sollen es semantische Sensordienste erlauben, auf Anfrage eines Benutzers Sensoren automatisch auszuwählen, zu konfigurieren und aufeinander abzustimmen. Zum Beispiel sollte das System die Anfrage „Wird es im Flussabschnitt XY der Donau eine Überflutung geben, falls es in den nächsten sieben Stunden weiter regnet?“ verstehen. Dazu muss es die Begriffe „Flussabschnitt“, „Donau“ und insbesondere „Überflutung“ und die Beziehung zwischen Regen und Überflutung kennen. Es kann Sensor Planning Services (SPS) und Sensor Alerting Services (SAS) einsetzen, um die Anfrage zu beantworten.
Semantik-basierte Suche nach Geoinformation
[Bearbeiten | Quelltext bearbeiten]Methoden der Informationswiedergewinnung (Information Retrieval) befassen sich mit der Suche relevanter Information aufgrund eines bestimmten Informationsbedürfnisses. Dazu gehören die Indizierung von Daten, die Relevanzbewertung von Ergebnissen und die Berechnung von Qualitätsmaßen wie Trefferquote und Genauigkeit. Geographische Informationswiedergewinnung (Geographic Information Retrieval) erweitert das klassische Problem um räumliche und zeitliche Komponenten. Eine beispielhafte Suche nach „Kneipen in der Wiener Altstadt“ erfordert sowohl thematische als auch topologische Übereinstimmung zwischen Anfrage und Suchergebnissen. Ein Verständnis der Datenquellen und Anfragen erfordert Methoden in den folgenden Bereichen:
- Das Ermitteln geographischer Referenzen im Text als Spezialfall von Computerlinguistik.
- Das Auflösen von Mehrdeutigkeiten von Ortsnamen in eine explizite geographische Referenz.
- Vage geographische Terminologie beschreibt die Herausforderung, geographische Referenzen von (häufig umgangssprachlichen) Ortsnamen mit undefinierten Grenzen, zum Beispiel der Wiener Altstadt, zu behandeln.
- Räumliche und textuelle Indizierung der raumzeitlichen Komponente von Geoinformation zusätzlich zur textbasierten Indizierung.
- Geographische Relevanzbewertungen erweitern typische Relevanzmaße um eine raum-zeitliche Komponente. Eine Bewertung ergibt sich somit nicht nur aus der textbasierten Übereinstimmung, sondern zum Beispiel auch nach der Entfernung zum Stadtzentrum.
Methoden zur Semantik-basierten Gewinnung von Geoinformation erfordern semantisch annotierte Datenquellen. Folglich kombinieren diese Methoden klassische Informationsgewinnung mit deduktiven und induktiven Schließverfahren, insbesondere des räumlichen Schließens.[4] Eine Anwendungen sind etwa ähnlichkeitsbasierte Benutzerschnittstellen zum Arbeiten mit Ortslexika.[5]
Gazetteers
[Bearbeiten | Quelltext bearbeiten]Siehe Hauptartikel: Ortslexikon.

Gazetteers sind Ortsverzeichnisse, die Ortsnamen mit einer geographischen Region (beispielsweise über ihre Bounding Box) und einer Objektart (z. B. Stadt) verbinden. Während Ortsverzeichnisse für unterschiedliche Zwecke geschaffen wurden, bieten die meisten Gazetteers wenigstens zwei Grundfunktionen an: eine zur Rückgabe der zu einem Namen gehörenden geographischen Referenz und eine zur Rückgabe der Objektart. Die Objektarten entstammen informellen Thesauri mit natürlichsprachlichen Beschreibungen. Einige Gazetteers verwenden jedoch auch formalere Wissensdarstellungen und Ontologien. Gazetteers tauchen als Komponenten in vielen Anwendungen auf, z. B. in Web-Kartiersystemen, räumlichen Suchmaschinen und Geoparsern. Anfragen wie Hotels in Wien werden bearbeitet, indem sie aus dem Ortsnamen Wien die zugehörige geographische Referenz (die auch nur ein umschreibendes Rechteck sein kann) ableiten. Danach suchen sie nach allen Hotels innerhalb dieser Region. Um mehrdeutige Ortsnamen wie Wien zu interpretieren, können sie zum Beispiel die IP-Adresse des Nutzers verwenden. a Die oben genannten Methoden zu einem besseren Verständnis der Suchanfragen gelten insbesondere auch für Gazetteers. Bekannte weltweit verwendete Gazetteers sind zum Beispiel der Getty Thesaurus of Geographic Names oder Geonames.org.
Nutzbarkeit
[Bearbeiten | Quelltext bearbeiten]Geographische Informationssysteme (GIS) bieten Operatoren zur Datenanalyse an, z. B. zur Formulierung von Abfragen anhand topologischer Beziehungen („Welche Gebäude liegen im Überschwemmungsgebiet?“) oder zur Berechnung metrischer Eigenschaften („Wie weit entfernt liegt mein Haus vom Überschwemmungsgebiet?“). Die vom Systementwickler beabsichtigte, die tatsächlich implementierte, die dokumentierte und die vom Nutzer erwartete Bedeutung solcher Operatoren können voneinander abweichen. Bis heute fehlen aber effektive Methoden, sie zu beschreiben. Grafiken mit Beispielen (wie die folgende für den räumlichen Überlappungsoperator in einem GIS) sind oft unklar oder mehrdeutig.

Mit einer maschinenlesbaren Semantik der Operatoren wären GIS außerdem in der Lage, dem Nutzer nur die für ausgewählte Objekte zulässigen Operatoren anzubieten. Zum Beispiel könnte die Darstellung von Linien gleichen Abstands auf der Erdoberfläche durch konzentrische Kreise in einer Mercator-Projektion vermieden werden, wie es im obigen Beispiel der Fall war. Beim Aufruf von GIS-Funktionen über Web-Dienste und bei deren automatischer Verkettung werden solche semantik-basierten Auswahlkriterien unabdingbar.
Prüfung der Datenintegrität
[Bearbeiten | Quelltext bearbeiten]Ein wesentlicher Aspekt der Qualität von Geoinformation ist die Integrität der einzelnen Objekte. Ob die Daten ein widerspruchsfreies Abbild der Realität liefern, lässt sich mit der Geosemantik automatisiert überprüfen. Die Sinnhaftigkeit der Attributwerte und räumliche Relation zu anderen Objekten werden mit Hilfe der logischen und topologischen Konsistenz beschrieben (näher beschrieben im ISO-Standard 19113). Logische Inkonsistenz betrifft einzelne Objekte, insbesondere die Werte ihrer Attribute. Zum Beispiel darf die Breite eines als Straße klassifizierten Objektes nicht unter drei Metern betragen, ansonsten ist dieses Objekt inkonsistent, weil es fälschlicherweise als Straße gekennzeichnet ist. Topologische Inkonsistenz bezieht sich auf wohldefinierte Beziehungen zwischen Objekten. Das eine Autobahn-Ausfahrt repräsentierendes Objekt muss notwendigerweise mit der Autobahn und einem weiteren Straßen-Objekt verbunden sein. Des Weiteren darf sich ein Straßen-Objekt nicht mit einem See-Objekt schneiden, falls das Datenmodell zusätzlich Brücken-Objekte erlaubt. Regeln können allerdings nicht nur auf Inkonsistenz prüfen. Im letzteren Fall kann das System für das Straßen-Objekt auch alternative Objektarten wie „Brücke“ oder „Fährverbindung“ vorschlagen und letztendlich den Nutzer bei der Beschreibung unterstützen.
Semantische Strategien
[Bearbeiten | Quelltext bearbeiten]Eine Vielzahl von Informationsgemeinschaften erstellt und nutzt Geodaten. Diese Gemeinschaften bilden sich um Aufgaben wie etwa Katasterverwaltung oder Verkehr-, Umwelt- und Ressourcenmanagement. Semantische Strategien helfen dabei, diese Informationsgemeinschaften zu etablieren und den beabsichtigten Nutzen der Daten explizit zu machen. Sie zielen letztlich darauf ab, erfolgreiche Kommunikation zu ermöglichen, ganz im Sinne von Paul Grice's Kooperationsprinzip: Die Kommunikationsteilnehmer unterstellen sich gegenseitig stillschweigend die Bedeutung bestimmter Ausdrücke. Wenn die Teilnehmer aber unterschiedliche Erwartungen haben oder aus unterschiedlichen kulturellen oder wissenschaftlichen Kontexten stammen, bedarf es spezieller Methoden, um die jeweiligen Deutungen aufeinander abzustimmen. Diese Methoden müssen die möglichen Interpretationen der Aussagen so einschränken, dass möglichst nur noch die gewünschte übrig bleibt. Zum Beispiel muss ein Ökologe über den beabsichtigten Sinn der Straßendaten einer Kartographiebehörde informiert sein, um sie für seine eigenen Zwecke nutzen zu können. Im Allgemeinen müssen Geodatennutzer ihre Daten in einer Weise interpretieren können, die mit den Absichten des Anbieters verträglich ist.
Qualitätsmaßstäbe: Was erreicht werden soll
[Bearbeiten | Quelltext bearbeiten]
Die verfügbaren semantischen Strategien lassen sich danach bewerten, welche Art von Übereinkunft sie zwischen den Kommunikationsteilnehmern ermöglichen. Jede Interpretation verknüpft Begriffe mit den zugrunde liegenden Ideen und einem bestimmten beobachtbaren Kontext. Im Fall von Geosemantik ist der beobachtbare Kontext die menschliche Umwelt. Daraus lassen sich drei Arten von Übereinkünften ableiten:
- Eine terminologische Übereinkunft über Basisbegriffe, die in Definitionen verwendet werden sollen, beispielsweise über den Namen einer Straße und die „Teil-Ganzes“-Beziehung zwischen Lebensräumen.
- Eine ontologische Festlegung (ontological commitment), welche die Objekte näher bestimmt, über die kommuniziert wird. Zum Beispiel, dass es bestimmte Arten von Straßen gibt, dass diese eine erkennbare Breite haben, und dass sie stets Teil eines Straßennetzes sind.
- Die Festlegung des Kontexts um sicherzustellen, dass Ausdrücke nur innerhalb der Grenzen einer bestimmten Domäne oder eines Anwendungsgebietes benutzt werden und so mögliche Mehrdeutigkeiten vermieden werden. Zum Beispiel, dass Straßenbreite sich auf die befestigte Straßenoberfläche bezieht, jedoch Radwege ausschließt.
Ein anschauliches Beispiel über unterschiedliche Auffassungen der gleichen Begriffe und die daraus entstehenden Konsequenzen zeigt der Film „Der Engländer, der auf einen Hügel stieg und von einem Berg herunterkam“. Die Einwohner des fiktiven walisischen Dorfes Ffynnon Garw verstanden etwas völlig anderes unter dem Begriff „Berg“ als zwei englische Landvermesser. Die beiden definierten „Berg“ vom Standpunkt der nationalen Höhenverteilung aus als Erhebung mit mehr als 1000 Fuß; die Einwohner jedoch als eine lokal dominante Erhebung. Die beiden Parteien benutzten beide dieselben Begriffe „Berg“, „Hügel“, „Höhe“ und waren sich sicherlich darüber einig, dass man Landschaftsgebilde nach Höhe klassifiziert oder dass Hügel kleiner als Berge sind. Aber der Kontext, in dem sie die Begriffe „Berg“ und „Hügel“ benutzten, blieb mehrdeutig. Als die Einwohner erkannten, dass der nationale Kontext außerhalb von Wales zählt und ihr Berg so zum Hügel würde, errichteten sie ein Steinmännchen auf der Spitze ihres Berges Garth Hill um ihn an die nationalen Klassifikationsanforderungen anzupassen. Sie hätten natürlich ebenso gut zwei unterschiedliche Kontexte gelten lassen können und die Erhebung lokal einen Berg und national einen Hügel nennen können. In sehr ähnlicher Weise hatten die Ingenieure des Mars Climate Orbiters es versäumt, den Kontext ihrer Längenmessung explizit zu machen, was die Benutzung von Längenstandards und passenden Umrechnungsvorschriften erforderlich gemacht hätte.
Semantisches Engineering: Wie man Übereinkunft erreicht
[Bearbeiten | Quelltext bearbeiten]Wie oben gezeigt, verlangt erfolgreiche Kommunikation nicht, dass man sich auf alle Begriffe innerhalb einer Informationsgemeinschaft einigt. Es reicht aus, sich auf einige wenige definierende Basisbegriffe, auf ontologische Festlegung bzgl. der Nutzung dieser Begriffe sowie auf Kontexte zu verständigen. Geosemantik kann als Ingenieurwissenschaft aufgefasst werden, die gerade einen solchen Einigungsprozess unterstützt.[6] Diese Aufgabe erfordert Methoden und Werkzeuge um Interpretationen gezielt einzuschränken. Solche Methoden können als Kombinationen dreier Strategien verstanden werden:
Konstruktion formaler Theorien über die Umwelt
[Bearbeiten | Quelltext bearbeiten]Eine erfolgreiche Strategie besteht darin, eine formale Theorie zu spezifizieren, die eine bestimmte Sicht auf die Umwelt beschreibt. Solch eine Theorie wird in der Informatik Ontologie genannt, um zu betonen, dass sie von existierenden Objekten in der Welt handelt, ähnlich der Idee von Ontologie als philosophischer Disziplin. Als logische Theorie, die die beabsichtigte Bedeutung eines formalen Vokabulars beschreibt,[7] kann sie genutzt werden, um Terminologien festzulegen und ontologische Festlegungen zu kommunizieren. In einer „Berg“-Ontologie hätten die walisischen Einwohner und die englischen Landvermesser sich auf Begriffe und ihre Anwendungsvorschrift für sichtbare Geländeerhebungen einigen können. Die Frage, ob eine Erhebung ein Berg ist oder nicht, hätte dann durch formales Schließen beantwortet werden können, vorausgesetzt, die Parteien hätten sich vorher auf bestimmte Höhenmessungen geeinigt. Der Ansatz, Geoontologien als Theorien des gesunden räumlichen Menschenverstandes zu betrachten, ähnlich der „naiven Physik“,[8] wird hier beschrieben.[9]
Selbständig entstehende Semantik (emergent semantics)
[Bearbeiten | Quelltext bearbeiten]Bei selbständig entstehender Semantik geht es darum, Semantik auszuhandeln. Zwar ist in allen Strategien ein bestimmtes Maß an Abstimmung notwendig, die selbständig entstehende Semantik stellt jedoch Werkzeuge bereit, um es Geodatennutzern zu ermöglichen, in einem gemeinschaftlichen Prozess mittels Folksonomien Bedeutung auszuhandeln. Folksonomien sind gemeinschaftlich geführte hierarchielose Sammlungen von Schlagwörtern, genannt Tags, welche mit Informationsquellen verknüpft werden. So kann zum Beispiel eine Benutzerin von Delicious ihre Webseite, die eine Fahrradtour um den Bodensee herum beschreibt, mit den Tags „Fahrrad“, „Ausflug“, „Österreich“, „Bregenz“ und „Bodensee“ markieren. In diesem Fall legt die Benutzerin eine Kategorie für ihre Webseite fest, indem sie den Begriff direkt mit der Beschreibung des Ausflugs verbindet. Im Vergleich zu klassischen Ontologien wird hier der Konsens nicht von oben nach unten durchgesetzt (wie zum Beispiel von der nationalen Ebene zur Dorfgemeinschaft im Film), sondern von unten nach oben – Benutzer einigen sich also untereinander.
Semantische Referenzierung
[Bearbeiten | Quelltext bearbeiten]Ziel ist es, verschiedene Kontexte eindeutig voneinander zu trennen. Dieses dritte Ziel semantischer Strategien kann nicht allein mittels Ontologien und Folksonomien erreicht werden, da formale Theorien und Tags nicht in der Lage sind, die gewünschte Bedeutung eindeutig festzulegen.[7][8][10] Insbesondere können die verwendeten Symbole nicht auf ihre Referenten in der realen Welt verweisen, was als Symbolverankerungsproblem (Symbol Grounding Problem) bekannt ist.[11] Geodaten müssen jedoch oft sehr eng im Sinne ganz bestimmter Beobachtungen interpretiert werden: Zum Beispiel bezieht sich „Garth Hill“ nur auf jenen Walisischen Berg; die Grenze Deutschlands auf eine vereinbarte Trennlinie von Staatsgebieten; der Begriff „1 Meter“ auf eine Reihe von physischen Phänomenen, darunter ein Platinbarren. Analog zu zeitlichen oder räumlichen Referenzsystemen erlauben es semantische Referenzsysteme,[12] Terminologien in nachvollziehbaren Beobachtungen zu verankern und somit ein „semantisches Datum“ festzulegen. Üblicherweise werden genaue Ortsbestimmungen mithilfe eines geodätischen Referenzellipsoids angegeben, d. h. eines mathematischen Bezugsrahmens, der durch ein geodätisches Datum, d. h. einen festgelegten Ort auf der Erdoberfläche, eine Standardausrichtung und eine Standardposition, in der wahrnehmbaren Umwelt verankert ist. Semantische Referenzsysteme sind in der Tat Verallgemeinerungen solcher Referenzsysteme. Ein Beispiel für solch einen semantischen Ansatz findet man hier.[13]
Methoden der Geosemantik
[Bearbeiten | Quelltext bearbeiten]Die vorangegangenen Abschnitte behandeln die Begründung der Geosemantik. Hier werden etablierte Methoden der Geosemantik im Detail beschrieben. Die Auswahl der Methoden orientiert sich an den oben beschriebenen Anwendungsfeldern.
Methoden für die Wiedergewinnung von Geoinformation
[Bearbeiten | Quelltext bearbeiten]Die Suche nach Geodaten erfordert die Formulierung von Suchanfragen mit Georeferenzen, die Indizierung georeferenzierter Dokumente und Geodaten, auf Geoinformation angepasste Relevanzbewertung und die Unterstützung des Nutzers bei der Evaluierung der Suchergebnisse. Alle Schritte werden von Methoden der Geosemantik unterstützt.
- Finden von Information
- Eine üblicherweise angewandte Methode ist die Unterstützung von Nutzern bei der Verfeinerung und Erweiterung von Anfragen durch das Vorschlagen von Konzepten für Ontologien oder eindeutige Ortsnamen von Gazetteers. Die Suchmaschine SPIRIT[14] ist ein Beispiel für semantisch unterstützte Anfragenerweiterung für Geoinformationsgewinnung. Eine verfeinerte Methode beruht auf expliziten semantischen Anfragen, die über ein Regel-ähnliches Format und mit einem aus Ontologien und Ortsverzeichnissen kommenden Vokabular dargestellt werden. Anfragen auf der Basis von Semantic Web Rule Language (SWRL) können räumliches Schließen unterstützen und liefern eventuell bessere Ergebnisse, wenn Erweiterungen für räumliche Funktionen integriert werden.
- Indizierung
- Indizierungsalgorithmen für die Kategorisierung von georeferenzierten Dokumenten beruhen zum Teil auf externen Wissensdatenbanken. Traditionelle Suchmaschinen verlassen sich auf die Indizierung von Text (unterstützt von linguistischen Prozessen wie Stemming oder Lemmatisierung). Data-Mining-Techniken wie Latent Semantic Indexing identifizieren Schlüsselkonzepte und Ortsnamen innerhalb von Dokumenten, die dann automatisch über semantische Annotierung mit räumlichen Ontologien verbunden werden.
- Bewertung
- Basierend auf den Konzepten der Anfrage und ihrer Übereinstimmung mit den indizierten Dokumenten kann ein Informationswiedergewinnungssystem die Relevanz des Dokumentes für die Anfrage bestimmen. Die räumliche Distanz der Georeferenzen kann dabei ein zusätzliches Bewertungskriterium darstellen.
Methoden für Semantik-gestützte automatische Datenintegration
[Bearbeiten | Quelltext bearbeiten]Bei der Informationswiedergewinnung sollen Nutzer beim Finden relevanter Information unterstützt und mit möglichst relevanten Dokumenten als Ergebnis bedient werden. Der Benutzer evaluiert die Ergebnisse und wählt die passendsten Treffer aus. Datenintegration entbindet den Nutzer von diesem Evaluationsschritt. In diesem Fall sollte das System automatisch die benötigten Dokumente und andere Datenquellen erkennen und sie in bestehende Arbeitsabläufe einbeziehen. Bei der Informationswiedergewinnung hilft die Semantik dem Nutzer Suchanfragen zu formulieren und die Ergebnisse zu verstehen. Bei der Datenintegration ist dies die Aufgabe des Reasoners. Im SWING-Projekt[15] wurden verschiedene Methoden basierend auf WSMX[16] getestet.
Methoden zur Konsistenzprüfung von räumlichen Daten
[Bearbeiten | Quelltext bearbeiten]Fehler im Datenerhebungsprozess können zu nicht miteinander verknüpften Flüssen oder zu Bäumen innerhalb von Seen führen. Reasoning-Algorithmen können die logische und topologische Konsistenz von Daten sichern, wenn einzelne geographische Objekte mit Konzepten innerhalb von Ontologien verknüpft werden sollen. Semantische Regeln können solche Widersprüche explizit darstellen. Reasoner führen diese Regeln aus und identifizieren Fehler.
Methoden zum Erstellen von Geoontologien
[Bearbeiten | Quelltext bearbeiten]Das Erstellen von Geoontologien ist ein zeitaufwändiges Unterfangen, das durch verschiedene Methoden unterstützt werden kann.
Die Wissenserfassung zum Bau von Wissensmodellen in der Geosemantik verläuft ähnlich wie in anderen Disziplinen. Eine Besonderheit von Domänen wie Geologie, Geographie oder Hydrologie ist die Verankerung in der Realität. Man unterscheidet zwischen Top-down- und Bottom-up-Strategien. Meistens wird jedoch eine Kombination aus beiden angewendet. Eine Einbindung eines bereits etablierten Vokabulars kann die Wiederverwendbarkeit der Ontologien gewährleisten.
- Top-Down – Zusammenarbeit mit Experten
- Eine Literaturrecherche im betroffenen Teilgebiet hilft den Wissensingenieuren (Knowledge Engineer) den gewünschten Umfang des Ontologien zu definieren und Kernbegriffe des Fachgebiets zu identifizieren. Dies wird idealerweise von Data-Mining-Techniken begleitet. Die Existenz impliziten Wissens sowie häufig vorkommende Inkonsistenzen zwischen Definitionen erfordern die Zusammenarbeit mit Experten des jeweiligen wissenschaftlichen Fachgebietes, um die häufig komplexen Bedeutung der Begriffe eindeutig zu erklären[17]
- Bottom-Up – Wissensbeschaffung als eine gemeinsame Leistung
- Beispiele wie Wikipedia zeigen, dass eine Informationsgemeinschaft manchmal selbst die beste Quelle für das Aufbauen von explizitem Wissen über eine Domäne ist. OpenStreetMap, ein kollaborativer Versuch zum Aufbau eines Kartensystems, fordert die Bearbeiter auf, einzelne Objekte zu kategorisieren. Die Kategorienamen können hierbei vom Nutzer frei gewählt werden, auch wenn die Nutzung bereits existierender Begriffe erwünscht ist. Dieses Vokabular ist eine wertvolle Quelle für Ontologien.
- Ermittlung und Wiederverwendung von existierenden Modellen
- Semantische Suchmaschinen wie Swoogle[18] ermöglichen bereits das Durchsuchen von existierenden Ontologien. Ein Beispiel aus der Geographie ist die SWEET-Ontologie.[19] Die Wiederverwendung einzelner Konzepte aus bereits bestehenden und etablierten Thesauri wie dem General Multilingual Environmental Thesaurus GEMET[20] oder dem AGROVOC der FAO gewähren breite Akzeptanz über Anwendungsgrenzen hinaus.
Inferenzmethoden für Geoontologien
[Bearbeiten | Quelltext bearbeiten]Geoontologien können genutzt werden um logische Schlüsse aus modellierten Tatsachen der wahrnehmbaren Umwelt zu ziehen und um Wissen aus geographischen Daten abzuleiten, oder mittels deduktiver Inferenz hinzuzufügen. Ein häufig genutzter Ansatz aus dem Semantischen Web ist entscheidbare Teillogiken der Prädikatenlogik erster Stufe wie Beschreibungslogik (DL) zu nutzen, um aus Taxonomien logisch schließen zu können. Zum Beispiel um zu entscheiden, ob eine Klasse eine andere beinhaltet (Subsumption), ob zwei Klassen Individuen teilen, ob Klassen leer sind, oder um alle Instanzen einer Klasse zu finden. Eine wichtige Methode ist der automatische Test auf Widerspruchsfreiheit einer Theorie in diesem Kalkül. Spezielle Tableau- und Resolutions-basierte automatische Beweiser sind für DL-Sprachen wie die Web Ontology Language OWL entwickelt worden.
Typische Aufgaben sind: Test auf Erfüllbarkeit, Subsumption, Instanztest, das Auffinden der kleinsten gemeinsamen Oberklasse und der spezifischsten Klasse, sowie ähnlichkeitsbasiertes Schließen.[21] Einige Aufgaben, wie das Regel-basierte Schließen und Abfragen, z. B. mit SWRL, können vergleichsweise effizient mit Hilfe von Horn-Klausel-basierten Verfahren gelöst werden, d. h. mit Vorwärts- oder Rückwärtsverkettung. Viele räumliche Theorien jedoch, beispielsweise „Region Connection Calculus“, Mereologie oder Euklidische Geometrien, benötigen die volle Ausdrucksfähigkeit der Prädikatenlogik erster oder sogar zweiter Ordnung (siehe „Region Based Geometry“[22]), und benötigen daher halbautomatische Schlussverfahren, wie Resolution oder natürliches Schließen. Oft werden in der Geosemantik auch vorberechnete „Composition Tables“ oder konzeptionelle Nachbarschaftsgraphen zum Beweisen benutzt, beispielsweise im 9-Schnittmodell der Regionstopologie.[23] Ein üblicher Ansatz besteht darin aus einer ausdrucksstarken aber unentscheidbaren Basistheorie aufgabenspezifische und effizienter berechenbare Teiltheorien herauszulösen, z. B. in Form von Horn-Klauseln oder Beschreibungslogiken.
Werkzeuge für die Geosemantik
[Bearbeiten | Quelltext bearbeiten]Werkzeuge und Standards im Bereich der Geosemantik, sind größtenteils dieselben wie jene, welche für das Semantische Web zum Einsatz kommen. Dazu zählen Standards des W3C wie XML, XML Schema, RDF, RDF-Schema, OWL oder die Semantic Web Rule Language (SWRL). Auf diesen Standards aufbauende Ontologien ermöglichen die Spezifikation der Konzepte und Relationen, die für die genannten Techniken erforderlich sind.
- Ontologie-Editoren ermöglichen es Informationswissenschaftlern, Domänenwissen in den genannten Standards zu spezifizieren. Als bekanntestes Beispiel für manuelles Bearbeiten gilt Protégé.
- Speziell auf raumbezogene Ontologien ausgelegte Werkzeuge sind ConceptVista,[24] oder Rabbit[25] eine Sprache, die dem Bearbeiten von Ontologien dient und von Ordnance Survey entwickelt wurde. Die meisten Editoren unterstützen nur eine eingeschränkte Anzahl an Standards zur Wissensrepräsentation. Da sich die Standards in ihrer Ausdrucksstärke unterscheiden, hängt die konkrete Wahl eines Editors nicht zuletzt davon ab, wie ausdrucksstark man arbeiten möchte.
- In der ersten Phase der Ontologiemodellierung können hingegen weniger spezialisierte, aber einfacher zu bedienende Editoren verwendet werden, die zudem meist unabhängig von Ontologiestandards sind. Concept-Maps erleichtern den Zugang zu Wissensmodellen und das gemeinschaftliche Arbeiten an einer Ontologie, ein Beispiel hierfür ist CMapTools (cmap.ihmc.us).
- Halbautomatische Werkzeuge wie Reuters Calais oder Ontogen ontogen.ijs.si unterstützen das Aufspüren von Kernkonzepten mittels Data-Mining. In der ersten Entwicklungsphase dienen sie dazu, Umfang und Schwerpunkt des Wissensgebiets zu bestimmen.
- Um die Konsistenz bestehender Daten zu überprüfen, werden Regeln verwendet, die beispielsweise in SWRL ausgedrückt werden können. In Entwicklungen wie GeoSWRL semwebcentral.org werden räumliche Relationen in SWRL integriert.
- Selbst in Verbindung mit umfassenden Regelwerken können Ontologien alleine keine semantischen Anwendungen realisieren. Notwendig sind Reasoner wie Pellet clarkparsia.com oder Jena, die maschinelle Schlussfolgerungen ermöglichen und damit Anwendungen der Geosemantik realisierbar machen. SIM-DL sim-dl.sourceforge.net ist ein speziell auf Geosemantik ausgelegter Reasoner, der auf Beschreibungslogik basiert und es ermöglicht Ähnlichkeitsmessungen durchzuführen.
Geschichte der Geosemantik
[Bearbeiten | Quelltext bearbeiten]Die Beschäftigung mit Geosemantik stützt sich auf Ergebnisse aus vielen Disziplinen. Dieser kurze Abriss der Geschichte der Geosemantik konzentriert sich auf Beiträge aus den letzten drei Jahrzehnten, die sich speziell mit thematischen Aspekten räumlicher Daten näher auseinandersetzten. Die Geschichte lässt sich in vier Phasen unterteilen, von denen sich jede durch besondere Schließverfahren und Repräsentationsformen der Semantik auszeichnet.
Von digitalen Karten zu räumlichem Schließen (bis 1990)
[Bearbeiten | Quelltext bearbeiten]Der Übergang von papierbasierten zu digitalen Geodaten in den sechziger Jahren[26] führte zunächst zu der Annahme, dass Geographische Informationssysteme vor allem Werkzeuge zum Speichern und Verändern von digitalen Karten seien. Es dauerte zwei Jahrzehnte, geprägt durch Fortschritte in der Datenbankforschung, bis der Unterschied zwischen graphischen Zeichen auf einer Landkarte und der dadurch dargestellten räumlichen und thematischen Information deutlich wurde. Zur gleichen Zeit begannen Wissenschaftler der Künstlichen Intelligenz und der Informatik an Schließverfahren und Problemen der Repräsentation von räumlichen Daten zu arbeiten. Vertreter dieser beiden Gruppen sowie Geographen, Linguisten, Philosophen und Kognitionswissenschaftler kamen im Juli 1990 im einflussreichen zweiwöchigen „Las Navas Meeting“ zusammen, um kognitive und linguistische Aspekte des geographischen Raums zu diskutieren und den damaligen Stand in einem wegweisenden Buch[27] zu publizieren.
Geographische Darstellung und Schließverfahren (von etwa 1990 bis 2000)
[Bearbeiten | Quelltext bearbeiten]Die Auseinandersetzung mit der Bedeutung georeferenzierter Daten und deren Anwendung in Schließverfahren wurde nun in der Geoinformatik, den Kognitionswissenschaften und der Künstlichen Intelligenz zu einem zentralen Thema. Die US-amerikanische National Science Foundation (NSF) förderte ab 1988 das „National Center for Geographic Information and Analysis“ (NCGIA) als Konsortium bestehend aus der University of California, Santa Barbara, der State University of New York in Buffalo und der University of Maine. Dadurch wurde anerkannt, dass der geographische Raum besondere Herausforderungen der Repräsentation und Analyse stellt. Das Forschungsprogramm von NCGIA war geprägt von fünf Kernthemen mit starkem Bezug zur Semantik. In dieser Zeit wurden außerdem die COSIT (Conference series on Spatial Information Theory[28]) und GIScience (Conference series on Geographic Information Science[29]) Konferenz-Reihen gegründet. Neben der Modellierung kognitiver und linguistischer Aspekte rückten nun auch kulturelle Aspekte und Differenzen ins Zentrum des Interesses.
Verbreitung von Geodaten im World Wide Web (ab ca. 1995)
[Bearbeiten | Quelltext bearbeiten]Mittlerweile hatten Industrie und Behörden erkannt, dass Versuche zur Standardisierung des Vokabulars (wie im Amtlichen Topographisch-Kartographischen Informationssystem) den Geodaten-Markt auf Nutzer mit ähnlichen Konzeptualisierungen einschränken, solange sie nicht mit semantischer Übersetzung einhergehen. Der entstehende Massenmarkt für Navigationssysteme konfrontierte gleichzeitig den Mann und die Frau auf der Straße mit semantischen Problemen. Das Open GIS Consortium (OGC, heute Open Geospatial Consortium) wurde unter dem Banner der Interoperabilität gegründet. Anbieter existierender Systeme sollten ihre zugrunde liegenden Datenmodelle nicht überarbeiten, dafür aber offene Schnittstellen implementieren, um die Kommunikation über technische und semantische Grenzen hinweg zu ermöglichen. Das OGC prägte den Begriff der Informationsgemeinschaften (information communities) und reagierte früh mit der Gründung einer Arbeitsgruppe zur Semantik. Dennoch konzentriert es sich bis heute auf syntaktische Interoperabilität und die Verknüpfung räumlicher Daten mit der allgemeinen Informationstechnologie und überlässt semantische Fragestellungen den Anwendern. In enger Zusammenarbeit mit dem OGC wurden jedoch frühzeitig ein Expertentreffen und zwei Konferenzen zur Interoperabilität organisiert. Zusätzlich begann die Forschung, sich schwerpunktmäßig mit Fragestellungen über Veröffentlichung und Nutzung von Geosemantik in dienste-orientierter Architekturen auseinanderzusetzen.
Verbreiten von Geoinformation im interaktiven Web (ab ca. 2005)
[Bearbeiten | Quelltext bearbeiten]Die Entstehung und verbreitete Akzeptanz interaktiver Kommunikationsformen in den ersten Jahren des neuen Jahrtausends resultierte im Sozialen Netz des Web 2.0. Auf dieser neuen Stufe des Internets wird Geoinformation von Nutzern nicht nur konsumiert, sondern aktiv beigesteuert (z. B. durch GPS Daten und Fotos). Dies verändert die ganze Geoinformatik[30] und mit ihr die Geosemantik. Der traditionelle hierarchische Ansatz der Geodatenproduktion und die damit verbundene hierarchisch kontrollierte Semantik wird nun in vielen Anwendungsgebieten durch eine breite, von Nutzern kommende, Datenbasis ergänzt. Das beeindruckende Wachstum von OpenStreetMap zeigt exemplarisch diese Entwicklung, aber deren semantische Herausforderungen. Der größte potenzielle Gewinn solcher durch Crowdsourcing gewonnenen Information für die Geosemantik liegt in der Analyse verschiedener Interpretationen von Begriffen in Form von Tags. Solche empirischen Daten sind von höchstem Wert für die Geosemantik und die dadurch gestellten Forschungsfragen werden einen Schwerpunkt der Geosemantikforschung kommender Jahre darstellen.
Offene Forschungsfragen
[Bearbeiten | Quelltext bearbeiten]In gewissem Sinne ist die ganze Geosemantik noch ein offenes Forschungsfeld. Wie anhand der oben stehenden Strategien, Methoden und Werkzeuge sichtbar wird, gibt es jedoch ein stetig wachsendes Fundament auf dem aktuelle und zukünftige Forschungsfragen aufbauen. Im Folgenden werden einige davon kurz skizziert, um einen Einblick in den aktuellen Stand der Forschung zu geben.
Semantik von Prozessen
[Bearbeiten | Quelltext bearbeiten]Geosemantik befasst sich mit Phänomenen in der Umwelt. Diese sind in den meisten Fällen jedoch nicht statisch, sondern Prozesse oder Ereignisse. Beispielsweise setzt das Verständnis von Messergebnissen aus Sensoren voraus, dass man die Prozesse versteht, durch die diese Ergebnisse gewonnen werden. Dies sind einerseits solche, die die Beobachtung in der realen Welt in ein elektronisches Signal umwandeln, als auch die Prozesse die zu der Beobachtung geführt haben. So setzte das Verständnis eines Anemometers voraus, dass man die druckabhängige Zirkulation von Luftmassen versteht. In viel stärkerem Maße gilt das für komplexe Prozesse wie den Klimawandel. Um beurteilen zu können, ob sich das Klima entscheidend ändert, muss man die zugrunde liegenden Prozesse und deren Auswirkungen verstehen. Während sich die Forschung hierzu derzeit noch mit statischen Modellen begnügt, wird sich die Geosemantik daher zunehmend mit der Formalisierung solcher Prozesse und deren Beobachtbarkeit befassen.
Vagheit
[Bearbeiten | Quelltext bearbeiten]Der Gebrauch von Begrifflichkeiten in den Geowissenschaften ist häufig vage und im Gegensatz zu Disziplinen wie der Bioinformatik fällt es schwer sich auf kanonische Definitionen zu einigen. So kann man beispielsweise sagen, dass eine gesunde und der Norm entsprechende menschliche Hand fünf Finger hat, für die Definition von Fluss ist dies nur bedingt möglich. Das Problem ist jedoch noch vielschichtiger. Einerseits lassen sich Begriffe nicht kontext- und domänenfrei festlegen. Andererseits erlauben die genutzten formalen Methoden, wie etwa Ontologien, nur eine Einschränkung der möglichen Interpretationen ohne jedoch unerwünschte vollständig ausschließen zu können. Die zukünftigen Forschungsfragen lassen sich in zwei Gebiete aufteilen. Einerseits muss man zunehmend Methoden erarbeiten, die erlauben effektiv mit vagen Begriffen umzugehen, andererseits muss sich die Geosemantik zukünftig der Herausforderung der semantischen Übersetzung stellen.
Semantische Übersetzung
[Bearbeiten | Quelltext bearbeiten]
Die Kernidee von semantischem Übersetzen (bzw. eines semi-automatischen semantischen Übersetzers) ist nicht eine allumfassende Übereinkunft über die Definition von Begriffen zu erlangen, sondern Heterogenität zuzulassen. Es gibt gute Gründe dafür warum einzelne Domänen innerhalb der Geowissenschaften unterschiedliche Auffassungen über die gleichen Dinge in der Welt haben. Das in der Einleitung beschriebene Straßenbeispiel zeigt dies eindrucksvoll. Straßen können sowohl als Verbindungen zwischen Orten als auch als dessen Gegenteil angesehen werden, nämlich als Hindernisse für Tiere die einen Lebensraum zerschneiden. Beide Sichten sind nicht vereinbar und dennoch für ihre Anwendungsfälle sinnvoll. Mit Hilfe von semantischer Übersetzung, semantischen Ausrichtungsverfahren und Ähnlichkeitsmaßen können jedoch Brücken zwischen diesen Weltsichten gebaut werden. Diese Brücken dienen nicht nur dem Austausch von Daten, sondern helfen auch Experten einen Konsens zu finden.
Vertrauenswürdigkeit
[Bearbeiten | Quelltext bearbeiten]In der Vision des Semantischen Web bildet das Problem der Vertrauenswürdigkeit von Information und Inferenzen die oberste Schicht Semantic Web Layer Cake. Es gibt viele mögliche Interpretationen des Begriffs Vertrauen oder Vertrauenswürdigkeit. In der Geosemantik zeigt sich derzeit die Tendenz, Vertrauenswürdigkeit als Maß für die Informationsqualität (im Sinne der Brauchbarkeit von Daten für eine bestimmte Aufgabe) zu definieren. Dies geht weit über klassische Ansätze zur Datenqualität hinaus, die sich gewöhnlich mit Fragen der Konsistenz oder Vollständigkeit befassen. Der zugrunde liegende Gedanke ist, dass vertrauenswürdige Nutzer auch künftig qualitativ bessere Ergebnisse zu einer Informationsgemeinschaft oder einem Projekt wie etwa OpenStreetMap beitragen als Nutzer, deren bisherige Beiträge sich als ungenau herausgestellt haben.
Evolution von Semantik
[Bearbeiten | Quelltext bearbeiten]Konzeptionalisierungen und die Verwendung der Sprache ändern sich im Laufe der Zeit. Das wird von heutigen Ontologien noch nicht erfasst und von Folksonomien noch nicht ausgenutzt. Viele Anwendungen im Bereich der Geoinformation müssen mit sich ändernder Semantik umgehen können, beispielsweise mit wechselnden Bezeichnungen von Ortsnamen oder überarbeiteten Klassifikationen. Zeitliches Indizieren von Ontologien wäre der einfachste Ansatz, wird aber normalerweise weder durchgeführt noch für Schlussfolgerungen verwendet. Darüber hinausgehende Ansätze für Modelle der Semantischen Entwicklung sind mit den derzeit verfügbaren Techniken größtenteils noch außer Reichweite.
Weblinks zu Forschungsgruppen, die sich mit Geosemantik beschäftigen
[Bearbeiten | Quelltext bearbeiten](Alphabetisch geordnet)
- ADVances in Information Systems Research Laboratory (ADVIS Lab), University of Illinois at Chicago
- Bremen Ontology Research Group, Universität Bremen
- Consortium of Universities for the Advancement of Hydrologic Science, Inc.- Hydrologic Information Science (CUAHSI-HIS)
- Digital Enterprise Research Institute, National University of Ireland, Galway
- GeoVISTA Center, the Pennsylvania State University, USA
- Knowledge Discovery and Data-Mining research unit (KDD LAB), eine gemeinsame Forschungsinitiative des ISTI und des Dipartimento di Informatica der Universität Pisa
- Large Scale Distributed Information Systems (LSDIS), Computer Science Department, University of Georgia
- Münster Semantic Interoperability Lab (MUSIL), Institut für Geoinformatik, Westfälische Wilhelms-Universität Münster
- National Center for Ontological Research (NCOR) by University at Buffalo and Stanford University
- OGC: Geosemantics DWG
- ONTOGEO - Geospatial Ontology Research Group, School of Rural and Surveying Engineering, National Technical University of Athens
- OntoSpace, ein Projekt des Transregional Collaborative Research Centers der Universität Bremen und der Universität Freiburg (sfbtr8.spatial-cognition.de ( vom 7. März 2012 im Internet Archive))
- Ordnance Survey – Great Britain's national mapping agency (ordnancesurvey.co.uk ( vom 6. Juni 2009 im Internet Archive))
- Semantic Computing Research Group (SeCo), Department of Media Technology, Helsinki University of Technology
- Semantic Information Research Laboratory of the Computer Science Department, University of Southern California (USC)
- Semantic Sensor Network Incubator Group
- STKO Lab at the University of California, Santa Barbara, US
- Technische Universität Wien, Institut für Geoinformation und Kartographie, Forschungsgruppe Geoinformation
- UMBC Ebiquity Research Group, University of Maryland, Baltimore County
- W3C Geospatial Incubator Group
Weitere Literatur
[Bearbeiten | Quelltext bearbeiten]- Al Gore: The Digital Earth: Understanding our planet in the 21st Century. (isde5.org ( vom 20. Juni 2009 im Internet Archive))
- F. Fonseca, M. A. Rodriguez, S. Levashkin (Hrsg.): GeoSpatial Semantics, Second International Conference, GeoS 2007, Mexico City, Mexico, November 29-30 2007. (= Lecture Notes in Computer Science. 4853). 2007, ISBN 978-3-540-76875-3.
- K. Janowicz, C. Keßler, M. Schwarz, M. Wilkes, I. Panov, M. Espeter, B. Bäumer: Algorithm, Implementation and Application of the SIM-DL Similarity Server. Second International Conference on GeoSpatial Semantics (GeoS 2007). Mexico City, Mexico, November 29-30, 2007. (= Lecture Notes in Computer Science). Springer 2007, S. 128–145. (ifgi.uni-muenster.de, PDF; 766 kB)
- K. Janowicz, S. Scheider, T. Pehle, G. Hart: Geospatial Semantics and Linked Spatiotemporal Data -- Past, Present, and Future. In: Semantic Web Journal. 2012. (geog.ucsb.edu, PDF; 274 kB)
- M. Kavouras, M. Kokla: Theories of Geographic Concepts: Ontological Approaches to Semantic Integration . 1. Auflage. CRC Press, 2007, ISBN 978-0-8493-3089-6.
- W. Kuhn: Semantic Reference Systems. In: International Journal of Geographical Information Science, Guest Editorial. 17(5), 2003, S. 405–409. (tandfonline.com)
- W. Kuhn: Geospatial Semantics: Why, of What, and How? In: Journal on Data Semantics III. (= Lecture Notes in Computer Science. 3534). Springer, Berlin / Heidelberg 2005, ISBN 3-540-26225-3. (researchgate.net)
- P. Maué, S. Schade, P. Duchesne: Semantic Annotations in OGC Standards, Open Geospatial Consortium (OGC), July 2009. (portal.opengeospatial.org)
- H. Pundt: The Semantic Mismatch as Limiting Factor for the Use of Geospatial Information in Disaster Management and Emergency Response. In: S. Zlatanova, J. Li (Hrsg.): Geospatial Information Technology for Emergency Response. ISPRS Book Series, Taylor & Francis, London / New York 2008, S. 243–256.
- M. A. Rodriguez, I. F. Cruz, M. J. Egenhofer, S. Levashkin (Hrsg.): GeoSpatial Semantics, First International Conference, GeoS 2005, Mexico City, Mexico, November 29-30, 2005, Proceedings. (= Lecture Notes in Computer Science. 3799). 2005, ISBN 3-540-30288-3.
- Shashi Shekhar, Xiong, Hui (Hrsg.): Geospatial Ontology, Geospatial Semantic Interoperability. In: Encyclopedia of GIS. Springer, 2008, ISBN 978-0-387-30858-6.
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ dpa/heg: Falsches Flugzeug: Nach Sydney gestartet, in Kanada gelandet. In: welt.de. 11. August 2009, abgerufen am 7. Oktober 2018.
- ↑ SWING-Projekt: 138.232.65.156/swing/index.html ( vom 1. Juli 2012 im Webarchiv archive.today)
- ↑ Amit Sheth, Cory Henson, and Satya Sahoo, Semantic Sensor Web. ( des vom 28. Juli 2011 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. (PDF; 919 kB). In: IEEE Internet Computing. Juli/August 2008, S. 78–83.
- ↑ A. G. Cohn, S. M. Hazarika: Qualitative spatial representation and reasoning: an overview. In: Fundamenta Informaticae. vol. 46, 2001, S. 1–29.
- ↑ K. Janowicz, C. Keßler, M. Schwarz, M. Wilkes, I. Panov, M. Espeter, B. Bäumer: Algorithm, Implementation and Application of the SIM-DL Similarity Server. In: Second International Conference on GeoSpatial Semantics (GeoS 2007). Mexico City, Mexico, November 29-30, 2007. (= Lecture Notes in Computer Science. 4853). Springer 2007, ISBN 978-3-540-76875-3, S. 128–145.
- ↑ W. Kuhn: Semantic Engineering. In: G. Navratil (Hrsg.): Research Trends in Geographic Information Science. (= Lecture Notes in Geoinformation and Cartography). Springer, Berlin 2009, ISBN 978-3-540-88243-5, S. 63–76.
- ↑ a b N. Guarino: Formal Ontology and Information Systems. In: N. Guarino (Hrsg.): Formal Ontology in Information Systems, Proceedings of FOIS’98, Trento, Italy, 6-8 June 1998. IOS Press, Amsterdam 1998, S. 3–15.
- ↑ a b P. J. Hayes: The Second Naive Physics Manifesto. In: J. R. Hobbs, R. C. Moore (Hrsg.): Formal theories of the Commonsense World. (= Ablex Series in Artificial Intelligence). Ablex, Norwood, N.J. 1985, ISBN 0-89391-213-1.
- ↑ M. J. Egenhofer, D. M. Mark: Naive Geography. In: A. U. Frank, W. Kuhn (Hrsg.): Spatial Information Theory: A Theoretical Basis for GIS. (= Lecture Notes in Computer Science. 988). Springer, Berlin 1995, ISBN 3-540-60392-1, S. 1–15.
- ↑ B. Smith: Ontology. In: L. Floridi (Hrsg.): Blackwell Guide to the Philosophy of Computing and Information. Blackwell, Oxford 2003, S. 155–166.
- ↑ S. Harnad: The Symbol Grounding Problem. In: Physica D. (42), 1990, S. 335–346.
- ↑ Werner Kuhn: Semantic Reference Systems. In: International Journal of Geographical Information Science. 17(5), 2003, S. 405–409.
- ↑ S. Scheider, K. Janowicz, W. Kuhn: Grounding Geographic Categories in the Meaningful Environment. In: K. S. Hornsby, C. Claramunt, G. Ligozat (Hrsg.): Spatial Information Theory, 9th International Conference, COSIT 2009, Aber Wrac'h, France, September 21-25, 2009. (= Lecture Notes of Computer Science. 5756). Springer, Berlin 2009, S. 69–87.
- ↑ C. B. Jones, A. I. Abdelmoty, D. Finch, G. Fu, S. Vaid: The spirit spatial search engine: Architecture, ontologies and spatial indexing. M. J. Egenhofer, C. Freksa, H. J. Miller (Hrsg.): Lecture Notes in Computer Science. vol. 3234, Springer Berlin / Heidelberg, Oktober 2004. (geo-spirit.org ( vom 9. August 2017 im Internet Archive))
- ↑ SWING-Projekt: 138.232.65.156/swing/index.html ( vom 1. Juli 2012 im Webarchiv archive.today)
- ↑ WSMX: http://www.w3.org/Submission/WSMX/
- ↑ S. Schade, P. Maué, J. Langlois, E. Klien: Knowledge acquisition with geologists – a field report. In: ESSI1 Semantic Interoperability, Knowledge and Ontologies, EGU General Assembly 2008. Februar 2008. (cosis.net)
- ↑ Swoogle: Archivierte Kopie ( vom 7. März 2009 im Internet Archive)
- ↑ SWEET: Archivierte Kopie ( vom 29. Mai 2007 im Internet Archive)
- ↑ General Multilingual Environmental Thesaurus: http://www.eionet.europa.eu/gemet
- ↑ K. Janowicz, M. Wilkes: SIM-DL_A: A Novel Semantic Similarity Measure for Description Logics Reducing Inter-Concept to Inter-Instance Similarity. The 6th Annual European Semantic Web Conference (ESWC2009). (= Lecture Notes in Computer Science. 5554). Springer, 2009, S. 353–367. (Archivlink ( vom 18. August 2011 im Internet Archive))
- ↑ B. Bennett, A. G. Cohn, P. Torrini, S. M. Hazarika: A Foundation for Region-Based Qualitative Geometry. In: W. Horn (Hrsg.): Proc. 14th European Conf. on Artificial Intelligence. IOS Press, Amsterdam 2000, S. 204–208.
- ↑ informatik.uni-bremen.de (Seite nicht mehr abrufbar, festgestellt im April 2018. Suche in Webarchiven)
- ↑ geovista.psu.edu ( des vom 21. Dezember 2009 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- ↑ ordnancesurvey.co.uk (Seite nicht mehr abrufbar, festgestellt im Januar 2019. Suche in Webarchiven)
- ↑ Nicholas Chrisman: Exploring Geographical Information Systems. 2. Auflage. Wiley, 2001, ISBN 0-471-31425-0.
- ↑ D. Mark, A. U. Frank: Cognitive and Linguistic Aspects of Geographic Space: Proceedings of the NATO Advanced Study Institute, Las Navas Del Marques, Spain, July 8-20, 1990. Springer, London 1991.
- ↑ cosit.info
- ↑ giscience.org
- ↑ M. Goodchild: Citizens as sensors: the world of volunteered geography. In: GeoJournal. 69(4), 2007, s. 211-221.
{kind=link}