Web semantico
Il web semantico è un'estensione del World Wide Web in cui i documenti pubblicati (pagine HTML, file, immagini, e così via) sono associati ad informazioni e dati (metadati) che ne specificano il contesto semantico in un formato adatto all'interrogazione e all'interpretazione (es. tramite motori di ricerca) e, più in generale, all'elaborazione automatica.
Con l'interpretazione del contenuto dei documenti che il Web semantico impone, saranno possibili ricerche molto più evolute delle attuali, basate sulla presenza nel documento di parole chiave, e altre operazioni specialistiche come la costruzione di reti di relazioni e connessioni tra documenti secondo logiche più elaborate del semplice collegamento ipertestuale. Il termine è stato coniato da Tim Berners-Lee, inventore del Web.[1]
Introduzione
[modifica | modifica wikitesto]Per la sua costruzione/definizione, si potrebbe pensare di utilizzare l'XML, un metalinguaggio che consente di descrivere (e con il dettaglio desiderato) le diverse parti di un documento. Un documento così descritto può poi essere elaborato per usi diversi: estrazione di informazioni secondo specifici criteri, riformulazione più o meno parziale per l'adattamento ad altri formati, visualizzazione in funzione delle capacità del terminale. XML però non consente una definizione semantica adeguata, per motivi che specificheremo dopo.
Sebbene un documento sia un buon modo per specificare informazioni, un documento, ancorché espresso in formato XML, è poco adatto al Web che, per sua natura, è distribuito e decentralizzato e, quindi, informazioni su una particolare entità possono essere localizzate ovunque.
Infatti, con XML è possibile descrivere adeguatamente i contenuti di un documento, ma la sintassi XML non definisce alcun meccanismo esplicito per qualificare le relazioni tra documenti. In questo non è di aiuto neppure il meccanismo dei collegamenti ipertestuali reso popolare dall'HTML perché amorfo, cioè non prevede la possibilità di descrivere il legame definito.
In altre parole, sebbene in un documento (ad es. una pagina HTML) sia possibile parlare di un Signor Ciampi ed esprimere semanticamente questo con opportuni tag, è poi difficile capire se due documenti che parlano di un Signor Ciampi si riferiscano alla stessa persona, con conseguente scarsa qualità dei risultati restituiti dai motori di ricerca.
Nella migliore delle ipotesi sarebbe possibile dedurlo se, tra gli altri, vi fossero dati anagrafici semanticamente definiti e sufficientemente precisi (ad es. il Codice Fiscale) o collegamenti ipertestuali debitamente descritti che li collegano.
Poiché, però, i diversi documenti sono redatti per scopi differenti, indipendentemente gli uni dagli altri e normalmente senza condividere un comune formato XML, informazioni utili quali l'indirizzo postale o la data di nascita finiscono per essere espresse in modo dissimile e non uniforme. L'indirizzo in un caso può essere semplicemente racchiuso dal tag <indirizzo>, in altri da <indirizzo_postale>, <direccion>, <address> o <adresse>, e poi è da considerare la possibilità di avere esplicitamente identificati <via>, <numero_civico>, ... rendendo ardua e non priva di rischi ogni deduzione automatica.
Nei prossimi paragrafi si illustreranno prima il linguaggio utilizzato per costruire il web semantico, quindi le previste evoluzioni, gli strumenti e il contributo che queste tecnologie potrebbero dare per rispondere definitivamente ad uno dei problemi irrisolti in ambito informatico: la gestione della conoscenza.
I primi linguaggi: RDF, N3
[modifica | modifica wikitesto]L'evoluzione del web in web semantico inizia con la definizione, da parte del W3C, dello standard Resource Description Framework (RDF), una particolare applicazione XML che standardizza la definizione di relazioni tra informazioni ispirandosi ai principi della logica dei predicati (o logica predicativa del primo ordine) e ricorrendo agli strumenti tipici del Web (ad es. URI) e dell'XML (namespace).
In estrema sintesi, secondo la logica dei predicati le informazioni sono esprimibili con asserzioni (statement in inglese) costituite da triplette formate da soggetto, predicato e valore (in inglese spesso identificati come subject, verb e object, rispettivamente). Ad esempio, le seguenti affermazioni su un Presidente della Repubblica italiano:
- Il Signor Ciampi vive a Roma.
- Il Signor Ciampi ha codice fiscale CMPCLZ20T09E625V.
possono essere schematicamente scomposte come
| Asserzione 1 | Asserzione 2 | |
| Soggetto | Il Signor Ciampi | Il Signor Ciampi |
| Predicato | vive a | ha codice fiscale |
| Valore | Roma | CMPCLZ20T09E625V |
allora, per alcuni di questi elementi, è possibile reperire arbitrariamente sul Web URI (risorse) che li identificano univocamente quali:
| Il Signor Ciampi | http://presidenti.quirinale.it/Ciampi/cia-biografia.htm |
| vive a | https://it.wiktionary.org/wiki/vivere |
| Roma | http://www.comune.roma.it |
| Ha codice fiscale | codice fiscale |
In questo caso, per
- Il Signor Ciampi si è scelto di referenziare la relativa biografia disponibile sul sito ufficiale del Quirinale
- Roma si è scelto di utilizzare il sito istituzionale del Comune di Roma
- vive a si è scelto di referenziare la definizione del verbo vivere disponibile su Wikizionario
- ha codice fiscale si è scelto di referenziare la definizione di codice fiscale disponibile su Wikipedia
Nei prossimi paragrafi si descrive come formalizzare le precedenti frasi in RDF nella sua forma canonica, in due suoi formati testuali alternativi (N3 ed N3 con prefissi) e graficamente.
Si segnala che appositi programmi come IsaViz[2] del W3C consentono di passare da un formato all'altro e sono utili per la sperimentazione del Web semantico.
Soluzione RDF canonica
[modifica | modifica wikitesto]Una possibile formalizzazione dell'esempio in RDF è:
1. <?xml version="1.0"?> 2. <rdf:RDF 3. xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:wikipedia="http://it.wikipedia.org/wiki/" 5. xmlns:wikizionario="http://it.wiktionary.org/wiki/"> 6. <rdf:Description 7. rdf:about="http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm"> 8. <wikizionario:vivere 9. rdf:resource="http://www.comune.roma.it/index.asp" 10. /> 11. </rdf:Description> 12. <rdf:Description 13. rdf:about="http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm"> 14. <wikipedia:codice_fiscale> 15. CMPCLZ20T09E625V 16. </wikipedia:codice_fiscale> 17. </rdf:Description> 18. </rdf:RDF>
| Riga 1 | <?xml version='1.0'?>, header xml standard | |
| Riga 2 | rdf:RDF è il nodo radice di un documento RDF definito nel namespace rdf di cui alla Riga 3 | |
| Riga 3 | xmlns:rdf= referenzia il namespace standard della sintassi RDF, identificandolo come rdf. Si ricorda che in XML si definisce un namespace per rendere più sintetica la scrittura del codice. D'ora in poi, infatti, ogni volta che si incontra rdf: lo si deve (mentalmente) sostituire con quanto scritto a destra dell'= di questa espressione, come già fatto nella Riga 2. | |
| Riga 4 e 5 | xmlns:wikipedia= e xmlns:wikizionario= referenziano due ulteriori namespace, identificandoli come wikipedia e wikizionario | |
| Righe 6-11 | Definiscono l'asserzione Il Signor Ciampi vive a Roma | |
| Riga 6 | rdf:Description è il tag del namespace rdf di cui alla Riga 3 che consente di specificare un'asserzione (soggetto, predicato, valore) | |
| Riga 7 | rdf:about è un attributo dell'elemento Description di Riga 6 da utilizzare per specificare il soggetto di un'asserzione quando, come in questo caso, è un URI | Il signor Ciampi |
| Riga 8 | vivere è il tag definito nel namespace wikizionario di cui alla Riga 4, utilizzato per definire il predicato | vive a |
| Riga 9 | rdf:resource è un identificativo del namespace rdf di cui alla Riga 3 per specificare il valore dell'asserzione, quando espresso come URI | Roma |
| Riga 10 | definizione della chiusura di un tag XML vuoto | |
| Riga 11 | Chiude il tag Description aperto alla Riga 6 | |
| Riga 12-17 | Definiscono l'asserzione Il Signor Ciampi ha codice fiscale CMPCLZ20T09E625V | |
| Riga 12 | rdf:Description è il tag del namespace rdf di cui alla Riga 3 che consente di specificare un'asserzione (soggetto, predicato, valore) | |
| Riga 13 | rdf:about è un attributo dell'elemento Description di Riga 12 da utilizzare per specificare il soggetto di un'asserzione quando, come in questo caso, è un URI | Il Signor Ciampi |
| Riga 14 | 'codice_fiscale è il tag definito nel namespace wikipedia di cui alla Riga 4, utilizzato per definire il predicato | Ha codice fiscale |
| Riga 15 | Il valore dell'asserzione | CMPCLZ20T09E625V |
| Riga 16 | Chiude l'elemento aperto alla Riga 14 | |
| Riga 17 | Chiude il tag Description aperto alla Riga 12 | |
| Riga 18 | Chiude l'elemento radice RDF aperto alla Riga 2 | |
Poiché le due frasi hanno lo stesso soggetto, allora possono essere riformulate nella seguente:
- Il Signor Ciampi vive a Roma ed ha Codice Fiscale CMPCLZ20T09E625V
alla quale corrisponde una formalizzazione RDF altrettanto sintetica (ed equivalente alla precedente):
<?xml version='1.0'?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:wikipedia="http://it.wikipedia.org/wiki/" xmlns:wikidizionario="http://it.wiktionary.org/wiki/"> <rdf:Description rdf:about="http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm""> <wikidizionario:vivere rdf:resource="http://www.comune.roma.it/index.asp"/> <wikipedia:codice_fiscale> CMPCLZ20T09E625V </wikipedia:codice_fiscale> </rdf:Description> </rdf:RDF>
Soluzione grafica
[modifica | modifica wikitesto]Per rappresentare graficamente asserzioni RDF, si utilizzano i grafi scegliendo i nodi per soggetto e valore, uniti da un arco orientato da soggetto a valore per il predicato.
Alcuni applicativi, come il già citato IsaViz, utilizzato in quest'esempio, adottano ellissi per i nodi che sono URI (http://www.comune.roma.it/index.asp), altrimenti dei rettangoli per i nodi che contengono semplici stringhe di caratteri (CMPCLZ20T09E625V). Detto ciò, al nostro esempio corrisponde il grafo:

Soluzione N3
[modifica | modifica wikitesto]N3 (noto anche come N-triples o Notation 3) propone una forma più facile da leggere rispetto ad RDF e l'esempio che stiamo considerando trova la seguente soluzione:
<http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm"> <https://it.wiktionary.org/wiki/vivere> <http://www.comune.roma.it/index.asp>. <http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm"> <codice fiscale> "CMPCLZ20T09E625V".
Ciascuna asserzione può essere scritta anche su un'unica linea, mettendo soggetto, predicato e valore l'uno di seguito all'altro. Si ricorda che in N3 è significativo anche il . (punto) che contrassegna la fine di ciascuna asserzione.
Soluzione N3 con prefissi
[modifica | modifica wikitesto]N3 con prefissi (N3 with prefix nella dizione inglese) è ancor più sintetico di N3 e riprende l'idea dei namespace XML per agevolare la compilazione utilizzando dei semplici editor. In questo caso l'esempio è tradotto come:
@prefix presidente: http://www.quirinale.it/presidente/ @prefix wikipedia: https://it.wikipedia.org/wiki/ @prefix wikidizionario: https://it.wiktionary.org/wiki/ @prefix comune_roma: http://www.comune.roma.it/ presidente:ciampi.html wikidizionario:vivere comune_roma:index.asp. presidente:ciampi.html wikipedia:codice_fiscale "CMPCLZ20T09E625V".
Dove con il comando @prefix si definiscono costanti di sostituzione che specifici strumenti automatici si occupano di operare per completare le asserzioni che le utilizzano. Così come per N3, anche per N3 con prefissi è significativo il . (punto) alla fine di ciascuna asserzione.
OWL
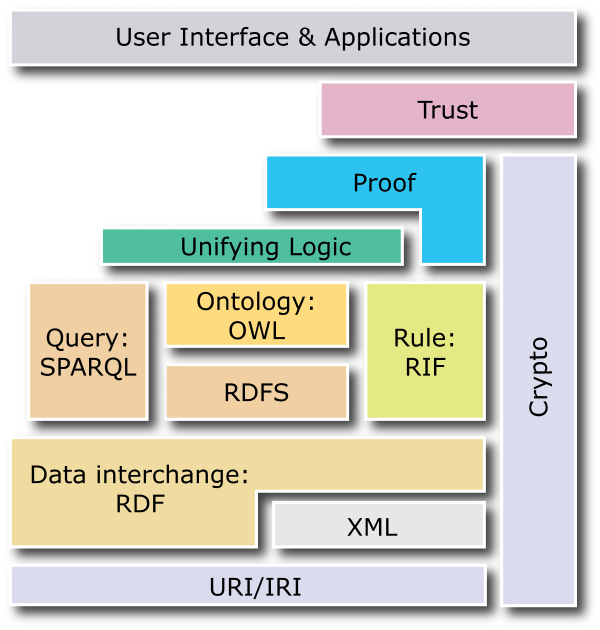
[modifica | modifica wikitesto]RDF non è che il primo passo. Il web semantico lo si sta costruendo a strati:

La logica predicativa del primo ordine è estremamente complessa, e RDF ne poteva esprimere una porzione molto ristretta. Non solo: questa logica, se presa complessivamente, non è nemmeno computabile, mentre possono essere computabili delle logiche costituite da sottoinsiemi degli operatori della logica del primo ordine. Questi sottoinsiemi della logica formale sono studiati dalle logiche descrittive, o description logics, ed una di queste è stata adottata per la formulazione di un nuovo standard, più ricco ed espressivo di RDF: OWL. OWL offre molti nuovi costrutti, due di questi, molto semplici da comprendere, sono l'equivalenza tra risorse e la relazione inversa.
- Per equivalenza tra risorse si intende la possibilità di affermare che due o più URI rappresentano lo stesso elemento.
- Per inversa si intende la possibilità di dire che se è vero (soggetto, predicato, oggetto), allora è anche vero (oggetto, predicato_inverso, soggetto).
L'importanza di un costrutto come l'equivalenza è presto spiegata anche solo considerando gli esempi fatti in precedenza. Ad es. poter dichiarare che
CF:CMPCLZ20T09E625V, wikipedia:carlo_azeglio_ciampi e quirinale:ciampi.htm sono equivalenti
consentirebbe di capire che le asserzioni
CF:CMPCLZ20T09E625V si chiama "Carlo Azeglio Ciampi" wikipedia:carlo_azeglio_ciampi vive a Roma quirinale:ciampi.htm è un "Presidente della Repubblica"
debitamente formalizzate ed ovunque reperite si riferiscono alla stessa risorsa, un Presidente della Repubblica (qualsiasi cosa questo significhi, ovvero qualsiasi cosa possa essere inferito da questa informazione) che vive a Roma e si chiama Carlo Azeglio Ciampi.
Per quanto riguarda l'inversa, invece basta pensare che quando si afferma che Romolo è fratello di Remo, si intende anche che Remo è fratello di Romolo, asserzione da fare esplicitamente in RDF per poter essere nota al sistema. Operazione fattibile ma tediosa. Per ovviare a ciò, sarebbe sufficiente poter definire una volta per tutte che se X è fratello di Y allora è vero anche Y è fratello di X.
Questi costrutti, insieme ad altri, sono stati introdotti per primi da linguaggi precedenti o contemporanei ad RDF quali DAML (definito dall'americana DARPA) ed OIL (sponsorizzata dalla Unione europea nell'ambito del programma IST), successivamente confluiti in DAML+OIL. Su questa base il W3C ha definito OWL (Web Ontology Language).
OWL esiste in tre forme, caratterizzate da diversi gradi di complessità e - conseguentemente - di computabilità. OWL-Lite è computabile (ossia è possibile trovare tutte le soluzioni in un tempo finito) ma poco espressivo; OWL-Lite è poco usato, poiché esiste OWL-DL, che è ugualmente computabile ma più ricco. Infine esiste OWL-Full, che copre tutta la ricchezza della logica predicativa, ma non è computabile e non è quindi adatto al ragionamento automatico.
Con OWL è possibile scrivere delle ontologie che descrivono la conoscenza che abbiamo di un certo dominio, tramite classi, relazioni fra classi e individui appartenenti a classi. La conoscenza così formalizzata è processabile automaticamente da un calcolatore, tramite un ragionatore automatico che implementa i processi inferenziali e deduttivi.
Modalità di impiego
[modifica | modifica wikitesto]Dagli esempi precedenti si evince che condizione necessaria per il buon utilizzo di RDF è la disponibilità on-line di riferimenti di qualità alle URI utilizzate/referenziate. In particolare, è importante che queste risorse siano note, condivise e stabili nel tempo. Ad esempio, il riferimento utilizzato per identificare il Presidente Ciampi, da questo punto di vista, non è dei migliori perché valido solo durante il mandato presidenziale, dopodiché sarà spostata in http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm dove già si trovano quelle dei suoi predecessori.
Dopo questa data l'asserzione continuerà a valere, ma si perderà il contributo informativo apportato dalla pagina referenziata sul web utile per una interpretazione dello stesso.
Molto più opportuno sarebbe utilizzare la biografia definita in Wikipedia oppure il Codice Fiscale con, ad es.,
Sebbene questa URI oggi non referenzi alcunché sul Web, la si potrebbe comunque utilizzare allo scopo perché RDF non presuppone alcuna verifica sulla effettiva disponibilità della risorsa stessa. In questo modo tutte le persone fisiche e giuridiche contemporanee e non solo personaggi, aziende, enti ed istituzioni "importanti" potrebbero essere univocamente identificati, potenziando notevolmente le possibilità di RDF (in ogni caso nulla vieterebbe all'Agenzia delle entrate di mettere a disposizione un servizio che a partire dalla URI citata restituisca automaticamente le relative informazioni anagrafiche).
Ciò detto, si potrebbe affermare che:
- La risorsa individuata dal codice fiscale CMPCLZ20T09E625V vive a Roma, ha una biografia in carlo azeglio ciampi ed un'altra in http://www.quirinale.it/presidente/ciampi.htm
ovvero:
@prefix agenzia: https://web.archive.org/web/20050212035111/http://www.agenziaentrate.it/servizi/ @prefix comune_roma: http://www.comune.roma.it/ @prefix presidente: http://www.quirinale.it/presidente/ @prefix wikipedia: https://it.wikipedia.org/wiki/ @prefix wikidizionario: https://it.wiktionary.org/wiki/ agenzia:CF#CMPCLZ20T09E625V wikidizionario:vivere comune_roma:index.asp agenzia:CF#CMPCLZ20T09E625V wikidizionario:biografia presidente:ciampi.htm agenzia:CF#CMPCLZ20T09E625V wikidizionario:biografia wikipedia:carlo_azeglio_ciampi
Un altro accorgimento da tenere presente nella scelta dei termini da utilizzare per la definizione delle relazioni è di ricorrere a dizionari già noti e diffusi, invece che inventarne ogni volta di nuovi. Ad es. per le informazioni anagrafiche personali tipiche dei biglietti da visita quali nome, cognome, indirizzo, e-mail, ruolo aziendale... è già disponibile vCard[4]. Non sono da dimenticare neppure le numerose applicazioni XML definite per abilitare l'EDI (Electronic Data Interchange, scambio dati elettronico) nell'ambito della pubblica amministrazione (e-government) o di associazioni di settore.
Da quanto esposto finora è facile intuire che, nella costruzione del web semantico, progetti come Wikipedia o Wikizionario non sono solo funzionali ma, adeguatamente sfruttati, anche abilitanti perché forniscono lemmi ben documentati per individuare risorse e predicati, garantendone la stabilità nel tempo e, grazie alla possibilità di dichiarare equivalenze nella stessa lingua e tra lingue diverse, di accrescere ulteriormente l'estensione di un'indagine automatica.
Strumenti
[modifica | modifica wikitesto]Ovviamente non è sufficiente avere solo una sintassi per esprimere predicati. Per rendere concreto ed utile quanto detto finora, occorrono anche strumenti in grado di gestire un insieme di asserzioni per rispondere alle richieste utente.
Per quanto riguarda N3, la gran parte di questi strumenti, come si può intuire dagli esempi di N3 ed N3 con prefissi, archiviano le asserzioni in una o più tabelle di un database relazionale. Alcune di queste soluzioni sono state censite dal progetto SWAD-Europe sponsorizzata dall'Unione Europea nell'ambito dell'iniziativa IST Archiviato il 22 giugno 2004 in Internet Archive..
Sui documenti scritti in OWL (o ontologie), invece, si può eseguire un vero e proprio ragionamento deduttivo inferenziale, realizzato tramite ragionatori automatici.
Linguaggi di query
[modifica | modifica wikitesto]Per utilizzare le basi di conoscenza formalizzate secondo questi standard è necessario un linguaggio per interrogarle. SPARQL (Simple Protocol And RDF Query Language) è uno dei linguaggi definiti per interrogare sistemi che gestiscono asserzioni RDF. Ad oggi sono disponibili altri linguaggi funzionalmente equivalenti ma SPARQL è candidato a divenire una raccomandazione W3C[5].
Per interrogare OWL, invece, manca ancora uno standard, ed i singoli ragionatori implementano linguaggi di query proprietari.
Web semantico e gestione della conoscenza
[modifica | modifica wikitesto]Da quanto detto si capisce perché se l'XML si rivolge alla descrizione di documenti, RDF (e sue evoluzioni) è particolarmente indicato per rappresentare dati, fornendo un metodo potenzialmente capace di risolvere un tema finora solo parzialmente soddisfatto da strumenti informatici: la gestione della conoscenza, ovvero la capacità non solo di trattare le diverse anagrafiche (di prodotto, clienti, fornitori, dipendenti,...) e di classificare i documenti tecnici o amministrativi, (analisi di mercato, specifiche tecniche, norme, procedure...) ma di arrivare anche a gestire i contenuti di questi documenti permettendo, ad es., il reperimento delle informazioni in funzione delle specifiche esigenze del richiedente, integrando quanto reso disponibile da fonti diverse[6].
Per quanto riguarda le anagrafiche, sarebbe molto semplice mappare i dati già disponibili in un RDBMS in asserzioni RDF - per ciascuna tabella:
- le chiavi univoche identificano una entità;
- i nomi delle colonne possono essere i predicati;
- il contenuto delle colonne i valori.
Per quanto riguarda i documenti, passando per XML potrebbero essere rielaborati in modo da ricavare le necessarie asserzioni RDF, sfruttando:
- la paragrafazione, normalmente standardizzata nella documentazione tecnica;
- l'utilizzo di dizionari comuni (un dato elemento è chiamato allo stesso modo in documenti diversi);
- l'analisi lessicale.
Ma la ri-formulazione in modo più efficace di strutture di dati esistenti non è che il primo e più semplice dei vantaggi che il web semantico ci offre. Tramite le ontologie abbiamo la possibilità di esprimere direttamente la struttura della nostra conoscenza e permettere alle macchine di elaborare automaticamente la conoscenza stessa, non più solo le semplici informazioni. In questo modo passiamo dalla semplice informatica (elaborazione automatica di informazioni) ad una epistematica: una elaborazione automatica di conoscenza.
Prospettive per il futuro
[modifica | modifica wikitesto]Il web, come si presenta oggi, richiede strumenti di lavoro più progrediti, per facilitare e velocizzare la navigazione attraverso gli innumerevoli documenti dati alla pubblicazione multimediale. Per il futuro, il web semantico si propone di dare un senso alle pagine web ed ai collegamenti ipertestuali, dando la possibilità di cercare solo ciò che è realmente richiesto. Non sempre la Rete ci porta dove ci attenderemmo e le difficoltà d'orientamento sono significative quando siamo alla ricerca di qualche cosa e non sappiamo dove reperirlo. Scorrere una lunga quantità di elenchi alla ricerca dell'informazione desiderata è ormai quotidianità, soprattutto quando la ricerca interessa un termine piuttosto comune. Con il Web semantico possiamo aggiungere alle nostre pagine un senso compiuto, un significato che va oltre le parole scritte, una "personalità" che può aiutare ogni motore di ricerca ad individuare ciò che stiamo cercando semplicemente perché lo è, scartando, di fatto, gli altri che non soddisfano la nostra richiesta. Tutto questo non in virtù di sistemi di intelligenza artificiale, ma semplicemente in virtù di una marcatura dei documenti, di un linguaggio gestibile da tutte le applicazioni e dell'introduzione di vocabolari specifici, ossia insiemi di frasi alle quali possano associarsi relazioni stabilite fra elementi marcati. Il web semantico per funzionare deve poter disporre di informazione strutturata e di regole di deduzione per gestirla, in modo da accostare quelle informazioni che un'interrogazione ha richiesto. Tim Berners-Lee ha sottolineato che uno degli elementi fondamentali del web semantico sarà la compresenza di più ontologie. Se si vuole un sistema dinamico in grado di raffinarsi e funzionare su scala universale, bisognerà pagare il prezzo di una certa dose di incoerenza. A partire dal 2006 il progetto di realizzazione del web semantico mediante la costruzione di ontologie è stato parzialmente revisionato. In un articolo pubblicato su International Journal on Semantic Web and Information Systems[7] dal titolo The Semantic Web Revisited[8], Tim Berners-Lee, Nigel Shadbolt e Wendy Hall hanno ridefinito alcuni aspetti del web semantico in funzione della dinamicità del World Wide Web. L'idea era quella di sviluppare e migliorare le ontologie in maniera collaborativa, grazie all'intervento di comunità di pratica. In seguito, questo nuovo approccio si è orientato sempre più a far sì che i dati vengano strutturati sotto forma di linked data anziché sotto forma di ontologie. Nell'articolo del 2009[9] emerge chiaramente che i linked data vengono considerati come le nuove colonne portanti su cui costruire il web semantico.
Agenti semantici
[modifica | modifica wikitesto]È da segnalare che molto lavoro è attualmente in corso per estendere le possibilità del web semantico applicando l'idea degli agenti semantici intelligenti (programmi in grado di esplorare ed interagire autonomamente con i sistemi informatici per, ad es., ricercare informazioni). Ruolo di questi agenti nel web semantico è di fornire più vaste capacità di inferenza realizzando quanto espresso in un articolo su Scientific American di Tim Berners-Lee intitolato The Semantic Web, dove si prospetta un futuro in cui Lucy fissa una visita medica alla madre utilizzando alcuni agenti capaci di "capire" la patologia, contattare i centri in grado di curarla e perfino di richiedere un appuntamento ai relativi agenti, salvo poi lasciarle la decisione di confermare[10].
Limiti
[modifica | modifica wikitesto]L'imprecisione del sistema è il prezzo da pagare alla sua universalità, i messaggi di "not found" (non trovato) non saranno completamente eliminati. Tutto questo per rendere possibile l'affiancarsi di più referenze e quindi non perdere, almeno in linea programmatica, la possibilità di più definizioni, di più comprensioni di uno stesso oggetto concreto.
Un altro tema molto importante e dibattuto è come gestire la fiducia sulle asserzioni o, più esattamente, sugli autori delle asserzioni.
Per ovviare il problema delle certificazioni che sarebbero necessarie a mantenere la veridicità delle ontologie, le asserzioni vengono trasformate a loro volta in termini legati al proprio autore attraverso il ruolo (proprietà) "Asserisce" che ha per codominio il termine "Asserzione". In questo modo è possibile attribuire a questo nuovo termine un Soggetto, un Predicato e un Oggetto utilizzando le normali relazioni. Attraverso questo procedimento, proposizioni del tipo "il bicchiere contiene del vino" vengono modificate in proposizioni del tipo "Marco ASSERISCE che il bicchiere (Soggetto) contiene (Predicato) del vino (Oggetto)". Se si vuole essere più precisi, bisognerebbe inserire nell'ontologia ben 4 asserzioni:
- Marco - asserisce - Asserzione
- Asserzione - haSoggetto - Bicchiere
- Asserzione - haPredicato - Contiene
- Asserzione - haOggetto - Vino
Note
[modifica | modifica wikitesto]- ^ Tim Berners-Lee, 2001.
- ^ IsaViz su w3.org
- ^ Immagine su w3.org
- ^ (EN) Representing vCard Objects in RDF/XML
- ^ (EN) SPARQL Query Language for RDF, W3C Recommendation 15 January 2008
- ^ (EN) OWL Web Ontology Language Use Cases and Requirements
- ^ International Journal On Semantic Web and Information Systems Archiviato il 5 marzo 2012 in Internet Archive.
- ^ http://The%20Semantic%20Web%20Revisited http://eprints.ecs.soton.ac.uk/12614/1/real/OLD_Semantic_Web_Revisted.pdf Archiviato il 27 ottobre 2011 in Internet Archive.
- ^ http://tomheath.com/papers/bizer-heath-berners-lee-ijswis-linked-data.pdf
- ^ The Semantic Web
{kind=link}
Bibliografia
[modifica | modifica wikitesto]- Tim Berners-Lee, L'architettura del nuovo Web, Feltrinelli, Milano, 2002
- Michael Daconta, The Semantic Web, Wiley Pub., Indianapolis, 2003
- Davies, John, Towards the semantic web, J. Wiley, Chichester-Hoboken, 2003
- Dieter Fensel, Spinning the semantic Web, MIT Press, Cambridge, 2003
- (EN) Tim Berners-Lee, The Semantic Web, in Scientific American, vol. 284, n. 5, maggio 2001, DOI:10.1038/scientificamerican0501-34 (archiviato il 4 dicembre 2008).
- Luca Spinelli, Panoramica sul web semantico, in «Login», Gruppo Editoriale Infomedia, 2005
- Johan Hjelm, Creating the semantic Web with RDF, Wiley, New York, 2001
Voci correlate
[modifica | modifica wikitesto]- Base di conoscenza
- Linked data
- KQML, linguaggio e protocollo di comunicazione usato per scambiare informazioni e conoscenza
- Logiche descrittive
- Ontologia (informatica)
- Resource Description Framework (RDF), standard per la descrizione della conoscenza nel web
- SKOS
- Topic Maps, tecnologia per l'organizzazione e la rappresentazione della conoscenza
- XML
- Web research
Altri progetti
[modifica | modifica wikitesto] Wikimedia Commons contiene immagini o altri file sul web semantico
Wikimedia Commons contiene immagini o altri file sul web semantico
Collegamenti esterni
[modifica | modifica wikitesto]- (EN) Sito ufficiale, su w3.org.
- (EN) William L. Hosch, Semantic Web, su Enciclopedia Britannica, Encyclopædia Britannica, Inc.
- (EN) Opere riguardanti Web semantico, su Open Library, Internet Archive.
- Rassegna stampa in tempo reale sul web semantico, su semanticism.org. URL consultato il 18 dicembre 2008 (archiviato dall'url originale il 26 dicembre 2008).
- RDF Primer del W3C, su w3.org.
- Un sistema semantico che raccoglie riferimenti a risorse di pubblica utilità quali strumenti e documenti nell'area Semantic Web
- SWAD-Europe su W3C, su w3.org.
- Websemantico.org.
- TermExtractor - software gratuito per l'estrazione di termini. Utile come punto di partenza per temi quali l'Ontologia
- Web Semantico e Rappresentazione della conoscenza: Percorso di studio introduttivo.
| Controllo di autorità | Thesaurus BNCF 48388 · LCCN (EN) sh2002000569 · GND (DE) 4688372-1 · BNE (ES) XX553987 (data) · BNF (FR) cb14521343b (data) · J9U (EN, HE) 987007566353105171 · NDL (EN, JA) 01017771 |
|---|